
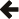


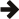
常见问题解答
- Outcome 在外部 API 中使用是否安全?
- Outcome 是否实现了过度对齐?
- Outcome 是否实现了无失败、强异常安全或基本异常安全保证?
- Outcome 是否具有稳定的 ABI 和 API?
- 我可以在 DLL/共享对象边界之间使用
result<T, EC>吗? - 为什么有两种类型
result<>和outcome<>,而不是只有一种? - 在我的公共接口中包含 Outcome 会对编译时间产生多大的影响?
- Outcome 适用于固定延迟/可预测执行的编码吗,例如高频交易或音频?
- 在我的代码中使用 Outcome 会引入什么样的运行时性能影响?
- 为什么禁用隐式默认构造?
- Outcome 的
checked<T, E>与提议的std::expected<T, E>相差多远? - 为什么 Outcome 不复制
std::expected<T, E>的设计? - 对于 const、包含 const 和包含引用的类型,Outcome 是否充满了未定义行为?
Outcome 在外部 API 中使用是否安全?
Outcome 专门为在数百万行代码库的公共接口中使用而设计。 result 的布局被硬编码为
struct trivially_copyable_result_layout {
union {
value_type value;
error_type error;
};
unsigned int flags;
};
... 如果 value_type 和 error_type 都是 TriviallyCopyable,否则
struct non_trivially_copyable_result_layout {
value_type value;
unsigned int flags;
error_type error;
};
如果 value_type 和 error_type 是 C 兼容的,则这是 C 兼容的。 std::error_code 可能 是 C 兼容的,但其布局未标准化(尽管标准中有一个关于其布局的规范性注释)。 因此,Outcome 无法为标准 Outcome 提供 C 宏 API,但我们可以为 实验性 Outcome 提供。
Outcome 是否实现了过度对齐?
Outcome 会传播您提供给它的类型的任何过度对齐,如上述布局中所指定的那样。 因此,使用您的编译器的普通对齐和填充规则。
Outcome 是否实现了无失败、强异常安全或基本异常安全保证?
(您可以在 cppreference.com 上阅读有关这些保证的含义)
如果对于以下操作
- 构造
- 赋值
- 交换
... value_type、error_type(以及 outcome 的 exception_type)中所有对应的操作都是 noexcept(true),那么 result 和 outcome 的操作就是 noexcept(true)。 这会传播底层类型的无失败异常保证。 否则,基本保证适用于除 Swap 之外的所有操作,规则与上面给出的 struct 布局类型相同,例如,首先构造 value,然后是标志,然后是 error。 如果 error 抛出异常,value 和状态位将如同未发生故障一样,与中止任何 struct 类型的构造相同。
人们认识到这些弱保证可能不适合某些人,因此 Outcome 实现了具有更强保证的 swap(),因为人们可以局部地改进,而无需太多工作,从 result 和 outcome 中自定义自己的类,实现更强的构造和赋值保证,并将 swap() 作为原始构建块。
强保证交换的核心 ADL 发现实现是 strong_swap(bool &all_good, T &a, T &b) 。 这可以被第三方代码使用自定义的强保证交换实现重载,与 std::swap() 相同。 因为当尝试在处理交换失败时恢复输入状态时,强保证交换可能会失败,所以如果恢复失败,all_good 布尔值将变为 false,此时两个 result/outcome 都会通过 has_lost_consistency() 标记为已损坏。
您有责任检查此标志,以查看已知良好状态是否已丢失,因为 Outcome 永远不会代表您这样做。 避免处理这种情况的简单方法是始终选择您的 value、error 和 exception 类型,使其具有非抛出移动构造函数和移动赋值。 这会导致不再使用强交换实现,因为它不再需要,而是使用标准交换。
Outcome 是否具有稳定的 ABI 和 API?
对于所有平凡可复制类型,Outcome v2.1 和 v2.2 之间的布局发生了变化,因为引入了基于联合的存储。 从 v2.2 开始,预计布局不会再次更改。
如果 v2.2 被证明在 24 个月内没有变化,Outcome 的 ABI 和 API 将被正式确定为 the v2 接口,并永远写入代码中。 此后,ABI 兼容性检查器 将在每次提交时运行,以确保 Outcome 的 ABI 和 API 保持稳定。 这目前预计在 2022 年发生。
请注意,稳定的 ABI 和 API 保证仅适用于独立的 Outcome,而不适用于 Boost.Outcome。 Boost.Outcome 依赖于 Boost 的其他部分,这些部分在不同版本之间不稳定。
另请注意,如果您配置 result 或 outcome 的类型也需要是 ABI 稳定的,如果 result 或 outcome 要是 ABI 稳定的。
我可以在 DLL/共享对象边界之间使用 result<T, EC> 吗?
使用 Windows DLL(以及在较小程度上使用 POSIX 共享库)的一个已知问题是,全局对象可能会被复制:可执行文件中有一个实例,DLL 中也有一个实例。 根据 C++ 标准,此行为并非不正确,因为标准不承认 DLL 或共享库的存在。 因此,当在使用 DLL 的程序中使用时,依赖于全局变量具有唯一地址的程序设计可能会受到损害。
Outcome 中没有任何内容依赖于全局变量的地址,加上保证的固定数据布局(请参阅上面的答案)意味着不同版本的 Outcome 可以在不同的 DLL 中使用,并且可能可以正常工作(仍然不建议您这样做,因为这违反了 ODR)。 但是,EC 最可能的候选者之一 – std::error_code – 确实依赖于全局变量的地址才能正确运行。
标准库需要为标准库提供的 std::error_category 实现(例如 std::system_category())实现全局唯一地址。 用户定义的错误代码类别可能 不 具有唯一的全局地址,因此会引入误操作。
boost::system::error_code,自 1.69 版本以来,选择性 提供保证,即它不依赖于全局变量的地址,如果 用户定义的错误代码类别 选择 使用 64 位比较机制。 这可以在 Boost.System 概要 中 error_category::operator== 的规范中看到。
或者,实验性 Outcome 中的 status_code,由于其更现代的设计,在任何配置中在共享库中使用都不会遇到任何问题。
为什么有两种类型 result<> 和 outcome<>,而不是只有一种?
result 是简单的成功或失败类型。
outcome 使用第三种状态扩展了 result,以传输,通常(但不一定)是某种“中止”或“异常”状态,函数可以返回该状态以指示操作不仅失败了,而且失败得灾难性,即请中止任何重试操作的尝试。
使用 outcome 的完美替代方案是为中止代码路径抛出 C++ 异常,实际上大多数程序应该完全这样做,而不是使用 outcome。 但是,在许多用例中,选择 outcome 会大放异彩
- 在 C++ 异常或 RTTI 不可用,但无需终止程序即可灾难性失败的能力很重要的情况下。
- 在即使在灾难性故障情况下也需要确定性行为的情况下。
- 在使用 Outcome 的代码的单元测试套件中,将测试失败累积到
outcome中以供稍后报告非常方便。 类似的便利性适用于 RPC 情况,其中需要累积 C++ 异常抛出以报告回发起端点。 - 在函数是“双重用途确定性”的情况下,即它可以确定性地使用,在这种情况下,人们基于
.error()切换控制流,或者它可以通过抛出异常(可能携带自定义负载)以非确定性方式使用。
在我的公共接口中包含 Outcome 会对编译时间产生多大的影响?
快速的答案是,这取决于您想要多少便利性。
便利头文件 <result.hpp> 依赖于 <system_error> 或 Boost.System,不幸的是,它包括 <string>,因此会引入相当多的其他解析速度慢的东西。 如果您的公共接口已经包含 <string>,那么额外包含 Outcome 的影响将很小。 如果您不包含 <string>,不幸的是,影响可能会相对较高,具体取决于您的公共接口文件的总体影响。
如果您一直非常小心地避免将大多数 STL 头文件包含到您的接口中,以最大限度地提高构建性能,那么 <basic_result.hpp> 可以具有尽可能少的依赖项,例如
<cstdint><initializer_list><iosfwd><new><type_traits><cstdio><cstdlib><cassert>
除了 <iosfwd> 之外,这些在大多数标准库实现中往往具有非常低的构建时间影响。 如果您仅包含 <basic_result.hpp>,并手动配置 basic_result<>,则编译时间影响将降至最低。
(有关更多详细信息,请参阅 basic_result<T, E, NoValuePolicy> 的参考文档。
Outcome 适用于固定延迟/可预测执行的编码吗,例如高频交易或音频?
人们非常小心地确保 Outcome 永远不会意外执行任何具有无限执行时间的操作,例如 malloc()、dynamic_cast<>() 或 throw。 Outcome 在全局禁用 C++ 异常和 RTTI 的情况下也能完美运行。
Outcome 的整个设计前提是,其用户乐于在成功的代码路径中交换小的、可预测的恒定开销,以换取可预测的失败代码路径。
相比之下,基于表的异常处理为成功的代码路径提供了零运行时开销,而为失败的代码路径提供了完全不可预测(且非常昂贵)的开销。
对于代码执行的可预测性至关重要的代码,无论代码路径如何,编写所有代码以使用 Outcome 都是一个不错的起点。 显然,在配置 outcome 或 result 时,请选择非抛出策略,例如 all_narrow 以保证 Outcome 永远不会抛出异常(或使用 result 的便捷 typedef,unchecked<T, E = varies>,它使用 policy::all_narrow)。
在我的代码中使用 Outcome 会引入什么样的运行时性能影响?
很难对从未见过的代码库中的性能影响说任何确定性的事情。 每个代码库都是独一无二的。 然而,为了提出某种衡量标准,我们计时了通过每种主要机制遍历十个堆栈帧,包括“什么都不做”(空)的情况。
堆栈帧被定义为编译器在最终被调用者中的返回点和基本调用者之间展开堆栈时调用的东西,因此例如,可能会销毁十个堆栈分配的对象,或者可能会展开十个堆栈深度级别。 这不是一个特别真实的测试,但它至少应该让人了解返回 Outcome 的 result 或 outcome 与返回普通整数或抛出异常相比的性能影响。
以下数据是针对 GCC 7.4、clang 8.0 和 Visual Studio 2017.9 的 Outcome v2.1.0。 使用更新的编译器的新 Outcome 的数据可以在 https://github.com/ned14/outcome/tree/develop/benchmark 中找到。
高端 CPU:Intel Skylake x64
这是一个高端 CPU,具有非常强大的缓存、预测、并行化和乱序执行能力,因此紧凑、重复的循环性能非常好。 它有一个能够完全包含测试循环的 μop 缓存,这意味着这些结果是 最佳情况 性能。
对数图比较了 GCC 7.4、clang 8.0 和 Visual Studio 2017.9 在 x64 上的性能,针对全局禁用异常、普通和链接时优化构建配置。
正如您所看到的,在基于表的异常处理实现(如这些)上,抛出和捕获异常非常昂贵,在 26,000 到 43,000 个 CPU 周期之间。 而这还是 热路径 情况,此基准测试是围绕热缓存代码的循环。 如果表被分页到存储器,您谈论的是 数百万 个 CPU 周期。
简单的整数返回(即什么都不做空情况)始终是最快的,因为它们做的工作最少,并且在 Intel Skylake CPU 上花费 80 到 90 个 CPU 周期。
请注意,在 GCC 和 clang 上,返回带有“成功(错误代码)”的 result<int, std::error_code> 的运行时开销比返回裸 int 不超过 5%。 在 MSVC 上,它花费了大约 20% 的额外开销,这主要是由于 VS2017.9 编译器中较差的代码优化。 请注意,“成功(实验性状态代码)”优化得更好,并且几乎没有比裸 int 更多的开销。
在 GCC、clang 和 MSVC 上,返回带有“失败(错误代码)”的 result<int, std::error_code> 的运行时开销比返回成功少于 5%。
您可能想知道,如果类型 E 具有非平凡的析构函数,从而使 result<T, E> 具有非平凡的析构函数,会发生什么? 我们测试了 E = std::exception_ptr,发现对于返回成功,开销比 E = std::error_code 少于 5%。 由于异常 ptr 的动态内存分配和释放,以及每个堆栈帧至少两个原子操作,返回失败显然要慢得多,在 300 到 1,100 个 CPU 周期之间,但这仍然比抛出和捕获异常好两个数量级。
我们得出结论,如果失败在您的 C++ 代码库中并非极其罕见,那么使用 Outcome 而不是抛出和捕获异常总体上应该更快
- 在所有编译器上,对于返回成功和失败,实验性 Outcome 在统计上与此高端 CPU 上的空情况没有区别。
- 对于返回成功,标准 Outcome 比 GCC 和 clang 上的空情况差不到 5%,对于返回失败,标准 Outcome 比 GCC 和 clang 上的空情况差不到 10%。
- 标准 Outcome 在 VS2017.9 上优化不佳,实际上比之前的点发布版本差很多,所以让我们希望微软尽快修复它。 它目前比空情况的开销不到 20%。
中端 CPU:ARM Cortex A72
这是一个四年前的中端 CPU,用于当时的许多高端手机和平板电脑,具有良好的缓存、预测、并行化和乱序执行能力,因此紧凑、重复的循环性能非常好。 它有一个能够完全包含测试循环的 μop 缓存,这意味着这些结果是 最佳情况 性能。
对数图比较了 GCC 7.3 和 clang 7.3 在 ARM64 上的性能,针对全局禁用异常、普通和链接时优化构建配置。
这款 ARM 芯片的性能非常稳定 – 空情况、成功或失败,都几乎花费相同的 CPU 周期。 选择 Outcome,在任何配置中,与根本不使用 Outcome 没有区别。 抛出和捕获 C++ 异常花费大约 90,000 个 CPU 周期,而空情况/Outcome 花费大约 130 - 140 个 CPU 周期。
关于这款 CPU,除了 Outcome 在其上零开销之外,没有什么可说的。 这同样适用于 ARM Cortex A15,当我在第一次同行评审后决定 Outcome v2 设计时,我对它进行了广泛的测试用例。 v2 设计的部分原因是因为 ARM 上如此稳定的性能。
低端 CPU:Intel Silvermont x64 和 ARM Cortex A53
这些是低端 CPU,具有主要是或完全按顺序执行的核心。 它们具有小型或没有 μop 缓存,这意味着 CPU 必须始终解码指令流。 这些结果代表了二十年前 CPU 更典型的执行环境,当时如果您从不抛出异常,基于表的 EH 会带来巨大的性能提升。
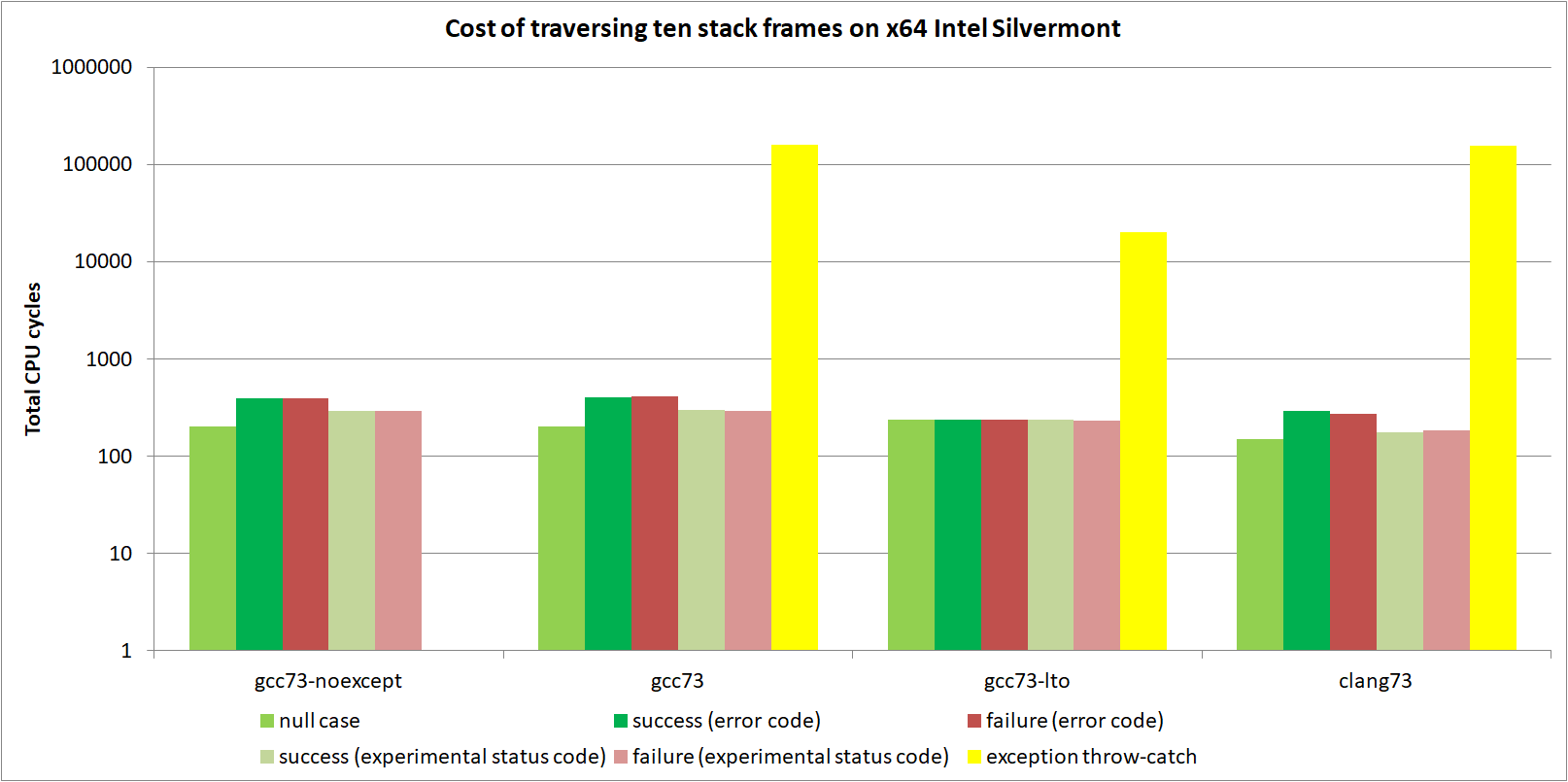
对数图比较了 GCC 7.3 和 clang 7.3 在 x64 上的性能,针对全局禁用异常、普通和链接时优化构建配置。
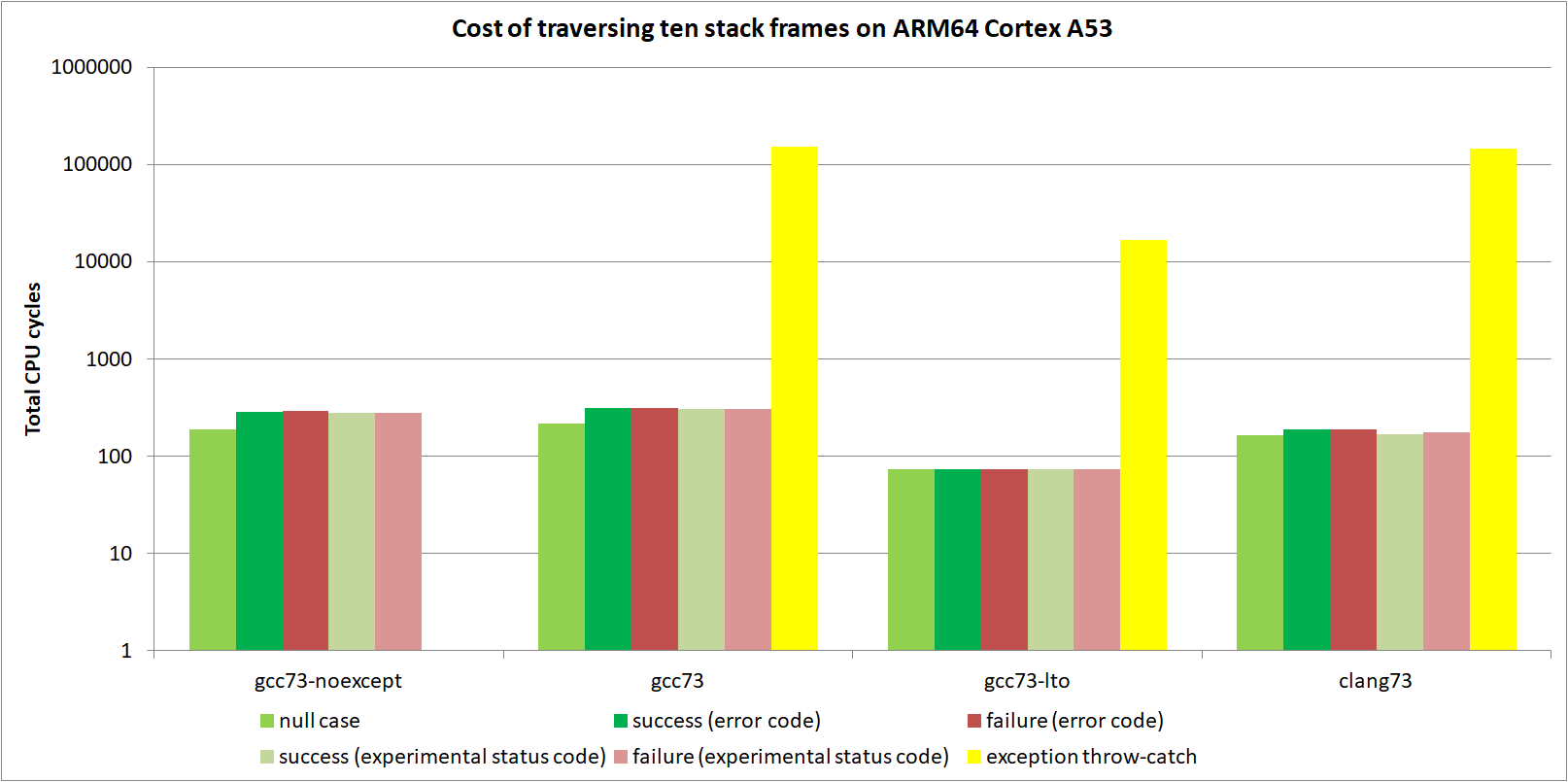
对数图比较了 GCC 7.3 和 clang 7.3 在 ARM64 上的性能,针对全局禁用异常、普通和链接时优化构建配置。
首先要提到的是,clang 为按顺序执行的核心生成了非常高性能的代码,远优于 GCC。 据说这是由于苹果公司多年来对 clang/LLVM 的大量投资,用于他们的设备。 无论如何,如果您以按顺序执行的 CPU 为目标,如果可以使用 clang,请不要使用 GCC!
对于空情况,Silvermont 和 Cortex A53 在 CPU 时钟周期方面非常相似。 抛出和捕获 C++ 异常也是如此(大约 150,000 个 CPU 周期)。 然而,Cortex A53 在 Outcome 方面的性能远优于 Silvermont,标准 Outcome 的开销为 15% 对 100%,实验性 Outcome 的开销为 4% 对 20%。
这种巨大差异的大部分实际上是由于调用约定差异。 x64 允许 CPU 寄存器从函数返回最多 8 个字节。 result<int> 消耗 24 个字节,因此在 x64 上,编译器将返回值写入堆栈。 但是,ARM64 允许在寄存器中返回最多 64 个字节,因此 result<int> 通过 ARM64 上的 CPU 寄存器返回。
在高端 CPU 上,内存以缓存行(32 或 64 字节)读取和写入,并且乱序执行核心将读取和写入合并并批量处理在一起。 在这些低端 CPU 上,内存按汇编程序指令顺序读取和写入,因此一次只能发生一个加载或一个存储到 L1 缓存。 这使得在按顺序执行的 CPU 上写入堆栈特别慢。 在高端 CPU 上“消失”的内存操作在低端 CPU 上花费大量时间。 这尤其惩罚了 Silvermont,而没有惩罚 Cortex A53,因为必须将多个值写入堆栈才能创建要返回的 24 字节对象。
从中得出的结论是,如果您以低端 CPU 为目标,基于表的 EH 仍然为成功代码路径带来显着的性能改进。 除非失败的确定性至关重要,否则您不应在按顺序执行的 CPU 上使用 Outcome。
为什么禁用隐式默认构造?
这是 Outcome v1 同行评审期间更令人感兴趣的讨论点之一。 v1 有一个正式的空状态。 这带来了许多优势,但人们认为它不符合 STL 惯用法,因为 std::optional<result<T>> 才是其含义,因此 v2 消除了任何合法的空状态可能性。
当时的 expected<T, E> 提案(2017 年 5 月)允许在 T 类型允许默认构造的情况下进行默认构造。 这样做专门是为了使 expected<T, E> 在 STL 容器中更有用,因为人们可以说调整向量大小,而无需提供 expected<T, E> 实例来填充新项。 然而,对于这种设计选择存在一些不安,因为它可能导致程序员使用某些类型 T,其默认构造状态被重载了额外的含义,通常是“待填充”,即通过选择魔术值来表示事实上的空状态。
对于 v2 重新设计,考虑了 v1 评审期间的各种论点。 与旨在成为通用 Either monad 词汇类型的 expected<T, E> 不同,Outcome 的类型主要用于从函数返回成功或失败。 因此,API 应鼓励程序员不要使用“待填充”的额外含义来重载成功类型,例如 result<std::optional<T>>。 因此,决定禁用隐式默认构造,但仍然允许显式默认构造,方法是让程序员使用额外的类型拼写出他们的意图。
因此,要显式地默认构造 result<T> 或 outcome<T>,请使用以下形式之一,这对于用例来说是最合适的
- 仅使用
in_place_type<T>构造,例如result<T>(in_place_type<T>)。 - 通过
success()构造,例如outcome<T>(success())。 - 从
void形式构造,例如result<T>(result<void>(in_place_type<void>))。
Outcome 的 checked<T, E> 与提议的 std::expected<T, E> 相差多远?
实际上,差距不大,在 2017 年 5 月的第一次 Boost.Outcome 同行评审之后,Expected 更接近 Outcome,并且 Outcome 有意提供 checked<T, E = varies> 作为语义等价物。
以下是剩余的差异,这些差异代表了 Boost 同行评审和 WG21 在此对象的正确设计上的共识意见分歧
checked<T, E>没有默认构造函数。 如果T具有默认构造函数,则 Expected 具有默认构造函数。checked<T, E>使用与std::variant<...>相同的构造函数设计。 Expected 使用std::optional<T>的构造函数设计。checked<T, E>构造后无法修改,除非通过赋值。 Expected 提供了一个.emplace()修饰符。- 当不明确时,
checked<T, E>允许从T和E进行隐式构造。 Expected 仅允许从T进行隐式构造。 checked<T, E>不允许T和E相同,并且如果它们可以相互构造(隐式构造会自我禁用),则会变得难以使用。 Expected 允许T和E相同。checked<T, E>抛出bad_result_access_with<E>而不是 Expected 的bad_expected_access<E>。checked<T, E>建模std::variant<...>。 Expected 建模std::optional<T>。 因此checked<T, E>不提供operator*()也不提供operator->checked<T, E>的.error()是宽的(即在无值时抛出),就像.value()一样。 Expected 的.error()是窄的(在无错误时为 UB)。 [checked<T, E>提供.assume_value()和.assume_error()用于窄(导致 UB)观察者]。
checked<T, E>使用success<T>和failure<E>类型糖进行消除歧义。 Expected 仅使用unexpected<E>。checked<T, E>未实现(容易发生意外误操作)允许隐式转换的比较运算符,例如checked<T> == T将无法编译。 请改为编写明确的代码,例如checked<T> == success(T)或checked<T> == failure(T)。checked<T, E>将E默认为std::error_code或boost::system::error_code。 Expected 不默认为E。
实际上,两者在设计上足够接近,以至于高度符合标准的 expected<T, E> 可以通过使用不同的功能包装 checked<T, E> 来实现
/* Here is a fairly conforming implementation of P0323R3 `expected<T, E>` using `checked<T, E>`.
It passes the reference test suite for P0323R3 at
https://github.com/viboes/std-make/blob/master/test/expected/expected_pass.cpp with modifications
only to move the test much closer to the P0323R3 Expected, as the reference test suite is for a
much older proposed Expected.
Known differences from P0323R3 in this implementation:
- `T` and `E` cannot be the same type.
- `E` must be default constructible.
- No variant storage is implemented (note the Expected proposal does not actually require this).
*/
namespace detail
{
template <class T, class E> using expected_result = BOOST_OUTCOME_V2_NAMESPACE::checked<T, E>;
template <class T, class E> struct enable_default_constructor : public expected_result<T, E>
{
using base = expected_result<T, E>;
using base::base;
constexpr enable_default_constructor()
: base{BOOST_OUTCOME_V2_NAMESPACE::in_place_type<T>}
{
}
};
template <class T, class E> using select_expected_base = std::conditional_t<std::is_default_constructible<T>::value, enable_default_constructor<T, E>, expected_result<T, E>>;
}
template <class T, class E> class expected : public detail::select_expected_base<T, E>
{
static_assert(!std::is_same<T, E>::value, "T and E cannot be the same in this expected implementation");
using base = detail::select_expected_base<T, E>;
public:
// Inherit base's constructors
using base::base;
expected() = default;
// Expected takes in_place not in_place_type
template <class... Args>
constexpr explicit expected(std::in_place_t /*unused*/, Args &&... args)
: base{BOOST_OUTCOME_V2_NAMESPACE::in_place_type<T>, std::forward<Args>(args)...}
{
}
// Expected always accepts a T even if ambiguous
BOOST_OUTCOME_TEMPLATE(class U)
BOOST_OUTCOME_TREQUIRES(BOOST_OUTCOME_TPRED(std::is_constructible<T, U>::value))
constexpr expected(U &&v)
: base{BOOST_OUTCOME_V2_NAMESPACE::in_place_type<T>, std::forward<U>(v)}
{
}
// Expected has an emplace() modifier
template <class... Args> void emplace(Args &&... args) { *static_cast<base *>(this) = base{BOOST_OUTCOME_V2_NAMESPACE::in_place_type<T>, std::forward<Args>(args)...}; }
// Expected has a narrow operator* and operator->
constexpr const T &operator*() const & { return base::assume_value(); }
constexpr T &operator*() & { return base::assume_value(); }
constexpr const T &&operator*() const && { return base::assume_value(); }
constexpr T &&operator*() && { return base::assume_value(); }
constexpr const T *operator->() const { return &base::assume_value(); }
constexpr T *operator->() { return &base::assume_value(); }
// Expected has a narrow error() observer
constexpr const E &error() const & { return base::assume_error(); }
constexpr E &error() & { return base::assume_error(); }
constexpr const E &&error() const && { return base::assume_error(); }
constexpr E &error() && { return base::assume_error(); }
};
template <class E> class expected<void, E> : public BOOST_OUTCOME_V2_NAMESPACE::result<void, E, BOOST_OUTCOME_V2_NAMESPACE::policy::throw_bad_result_access<E, void>>
{
using base = BOOST_OUTCOME_V2_NAMESPACE::result<void, E, BOOST_OUTCOME_V2_NAMESPACE::policy::throw_bad_result_access<E, void>>;
public:
// Inherit base constructors
using base::base;
// Expected has a narrow operator* and operator->
constexpr void operator*() const { base::assume_value(); }
constexpr void operator->() const { base::assume_value(); }
};
template <class E> using unexpected = BOOST_OUTCOME_V2_NAMESPACE::failure_type<E>;
template <class E> unexpected<E> make_unexpected(E &&arg)
{
return BOOST_OUTCOME_V2_NAMESPACE::failure<E>(std::forward<E>(arg));
}
template <class E, class... Args> unexpected<E> make_unexpected(Args &&... args)
{
return BOOST_OUTCOME_V2_NAMESPACE::failure<E>(std::forward<Args>(args)...);
}
template <class E> using bad_expected_access = BOOST_OUTCOME_V2_NAMESPACE::bad_result_access_with<E>;
为什么 Outcome 不复制 std::expected<T, E> 的设计?
有许多原因
Outcome 的目标受众与 Expected 不同。 我们的目标是乐于使用 Boost 的开发人员和用户。 Expected 的目标是标准库用户。
Outcome 认为单子用例不如 Expected 认为的那么重要。 具体来说,我们认为现实世界中 99% 的 Expected 用例将是从函数返回失败,而不是作为某种增强型或“丰富”的 Optional。 因此,Outcome 建模了 Variant 的子集,而 Expected 建模了扩展的 Optional。
Outcome 认为,如果您正在考虑使用类似于 Outcome 的东西,那么对于您来说,编写失败代码的比例将与编写成功代码的比例相同,因此在 Outcome 中,为失败编写代码与为成功编写代码完全相同。 Expected 假设成功比失败更常见,并且在为失败编写代码时让您键入更多内容。
Outcome 付出了相当大的努力来帮助最终用户在使用过程中键入更少的字符。 这导致更紧凑、更简洁、更简洁的代码。 这样做的代价是比使用 Expected 编程时更陡峭的学习曲线和更复杂的心理模型。
Outcome 具有促进每个使用不相称的 Outcome(或 Expected)配置的多个第三方库之间更容易互操作的工具。 Expected 没有做任何这些事情,但随后的 WG21 论文确实提出了各种互操作机制,其中之一 Outcome 实现了,因此使用 Expected 的代码将与使用 Outcome 的代码无缝互操作。
Outcome 的设计受益于 Optional 和 Expected 之后的后见之明,在这些后见之明中,发现它们的隐式转换容易编写意外的错误代码。 Outcome 同时允许更多隐式转换以方便使用和便利性(在这些转换明确安全的情况下),并阻止 Boost 同行评审报告为危险的其他隐式转换。
对于 const、包含 const 和包含引用的类型,Outcome 是否充满了未定义行为?
简短的答案是,由于 2019 年 11 月在贝尔法斯特 WG21 会议上对 C++ 20 所做的更改,在 C++ 20 及更高版本中不再是这样了。
较长的答案是,在 C++ 20 之前,在包含 const 成员类型的类型上使用放置 new,其中结果指针被丢弃是未定义行为。 随着国家机构评论的解决,情况不再如此,现在对于 C++ 20 及更高版本,Outcome 没有这种特定的 UB。
但这仍然会影响 C++ 20 之前的版本,尽管没有主要的编译器受到影响。 尽管如此,如果您希望避免 UB,请不要在 Outcome 类型(或任何 optional<T>、或 vector<T> 或任何 STL 容器类型)中使用 const 类型。
更多细节
在 C++ 14 标准之前,放置 new 到曾经包含 const 类型的存储中始终是未定义行为。 因此,在 result<const_containing_type> 或实际上 optional<const_containing_type> 中使用放置 new 始终是 C++ 14 之前的未定义行为。 来自 C++ 11 标准的 [basic.life]
在 const 对象占据的存储位置或在这样的 const 对象在其生命周期结束后曾经占据的存储位置创建新对象会导致未定义行为。
由于这种限制过于严格,从 C++ 14 开始,[basic_life] 现在声明
如果在对象的生命周期结束后,并且在对象占据的存储被重用或释放之前,在原始对象占据的存储位置创建了一个新对象,则指向原始对象的指针、引用原始对象的引用或原始对象的名称将自动引用新对象,并且一旦新对象的生命周期开始,就可以用于操作新对象,如果
— 新对象的存储完全覆盖了原始对象占据的存储位置,并且
— 新对象的类型与原始对象的类型相同(忽略顶层 cv 限定符),并且
— 原始对象的类型不是 const 限定的,并且,如果是类类型,则不包含任何类型为 const 限定或引用类型的非静态数据成员,并且
— 原始对象和新对象都不是可能重叠的子对象
撇开我对赋予非 const 非引用类型的放置 new 以神奇的指针重命名能力的个人反对意见不谈,结果是,如果您希望为包含 const 类型或引用的类型的放置 new 定义行为,则必须存储放置 new 返回的指针,并将该指针用于所有进一步引用新创建的对象。 这显然会为 result<const_containing_type> 增加八个字节的存储空间,鉴于为保持其小巧而付出的所有努力和关注,这是非常不受欢迎的。 另一种选择是使用 std::launder ,它在 C++ 17 中添加,以在每次使用该存储之前将我们放置 new 的存储“清理”干净。 这迫使编译器在每次使用时重新加载放置 new 存储的对象,而不是假设它可以是常量传播的,这会影响代码生成质量。
如上所述,这个问题(就其适用于包含用户提供的 T 类型(可能是 const)而言)已从 C++ 20 开始得到解决,并且极不可能有任何 C++ 编译器会在 C++ 17 或 14 中对此处的任何 UB 采取行动,因为如此多的 STL 容器会崩溃。