
目录
- Boost.Polygon 主页
- 设计概述
- 各向同性
- 坐标概念
- 区间概念
- 点概念
- 线段概念
- 矩形概念
- 90 度多边形概念
- 带孔 90 度多边形概念
- 45 度多边形概念
- 带孔 45 度多边形概念
- 多边形概念
- 带孔多边形概念
- 90 度多边形集合概念
- 45 度多边形集合概念
- 多边形集合概念
- 90 度连通性提取
- 45 度连通性提取
- 连通性提取
- 90 度属性合并
- 45 度属性合并
- 属性合并
- Voronoi 主页
- Voronoi 基准测试
- Voronoi 构建器
- Voronoi 图
其他资源
Polygon 赞助商

多边形集合算法分析
Boost.Polygon 库中最重要的一些算法是通用扫描线算法的实例化,这些算法提供了执行曼哈顿和 45 度线段相交、n 层地图叠加、连通图提取和裁剪/布尔运算的功能。 这些算法对于等于输入顶点加相交顶点的 n 具有 O(n log n) 的运行时复杂度。 由于实现数值鲁棒性相关的复杂性,任意角度线段相交算法未实现为扫描线。 通用线段相交算法在 y 维中实现为递归自适应启发式分治,然后在每个细分中按 x 坐标对线段进行排序,并从左到右扫描。 通过在 x 和 y 中对问题空间进行一维分解,该算法在通常情况下近似于最佳 O(n log n) Bentley-Ottmann 线段相交运行时复杂度。 Bentley-Ottmann 算法可以避免特定输入示例(这些示例会破坏问题空间的一维分解)导致病态二次运行时复杂度。
下面显示的是输入大小呈二次方增长时,运行时间与输入大小的对数-对数图。 输入是通过在与每次试验指定的矩形数量成比例的正方形区域内伪随机分布小轴平行矩形生成的。 这样,随着输入大小的增长,产生相交的概率保持不变。 由于预期相交顶点是输入顶点的常数因子,因此我们可以根据输入顶点检查运行时复杂度。 执行的操作是通过曼哈顿、45 度和任意角度布尔算法(分别标记为“boolean 90”、“boolean 45”和“boolean”)对输入矩形进行并集(布尔 OR)运算。 该图还显示了在添加分治递归细分之前任意角度布尔算法的性能,这在 论文 中有所描述,该论文在 2009 年 boostcon(boostcon) 上 发表。 最后,将输入点排序所需的时间显示为 O(n log n) 运行时间的通用参考,以便将数据置于上下文中。
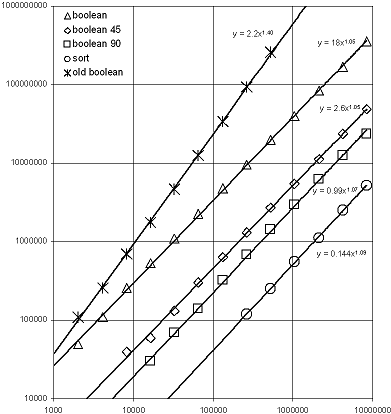
我们可以在对数-对数图中看到,排序和 Boost.Polygon 库提供的三个布尔算法具有接近 45 度“线性”缩放比例,经验指数略大于 1.0,并且可以观察到对于这些输入,缩放比例与 O(n log n) 成正比。 在 boostcon 2009 上提出的“旧布尔”算法表现出接近预期 O(n1.5) 缩放比例的缩放比例。 由于分治方法提供的加速是算法级的,因此在 200,000 个矩形或更大输入的情况下,可以实现论文中提到的 10 倍潜在性能提升。 即使对于 2K 矩形的小输入,该算法也快了 2 倍,现在可以预期在小规模下与 GPC 一样快,而在大规模下算法更快。
从图中,我们可以将各种布尔算法的常数因子性能与 std::sort 的运行时间进行比较,作为 O(n log n) 算法的基线。 如果将排序视为一个单位的 O(n log n) 算法工作,我们可以看到曼哈顿布尔运算大约需要五个单位的 O(n log n) 工作,45 度布尔运算大约需要十个单位的 O(n log n) 工作,任意角度布尔运算大约需要七十个单位的 O(n log n) 工作。 对输入顶点进行排序是布尔算法的第一步,因此为最佳布尔算法的运行时间提供了一个硬下限。
关于任意角度布尔算法性能的最后一点需要注意的是,可以通过包含 boost/polygon/gmp_override.hpp 并链接到 lgmpxx 和 lgmp 来使用 GMP 无限精度有理数据类型进行数值鲁棒计算。 这 100% 保证算法将成功并在多边形边界上产生捕捉到整数网格的输出,并在引入交点的多边形边界上产生至少一个整数网格的误差。 但是,无限精度数据类型永远不会用于谓词(有关鲁棒谓词的描述,请参阅 boostcon 演示文稿或论文),并且仅在极少数情况下用于构造相交坐标值,即两条线段相交的 long double 计算无法在两条线段的一个整数单位内产生交点。 这意味着使用无限精度来确保 100% 的鲁棒性实际上没有运行时损失。 大多数输入将在算法中处理,而无需 recurrir a GMP。
| 版权 | 版权所有 � 英特尔公司 2008-2010。 |
|---|---|
| 许可证 | 根据 Boost 软件许可证 1.0 版分发。(请参阅随附文件 LICENSE_1_0.txt或复制于 https://boost.ac.cn/LICENSE_1_0.txt) |