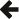


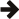
消息传递性能在高吞吐量分布式计算中至关重要。为了评估 Boost.MPI 的性能,我们修改了标准的 NetPIPE 基准测试(3.6.2 版本),使其使用 Boost.MPI,并将其性能与原始 MPI 进行了比较。我们运行了 NetPIPE 基准测试的五个不同变体。
MPI_BYTE)而不是基本数据类型。Char 类型代替基本 char 类型。该 Char 类型包含单个 char,一个用于使其可序列化的 serialize() 方法,并特化了 is_mpi_datatype 以强制 Boost.MPI 为其构建派生 MPI 数据类型。Char 类型代替基本 char 类型。该 Char 类型包含单个 char 并且是可序列化的。与数据类型情况不同,is_mpi_datatype 未 特化,强制 Boost.MPI 执行大量序列化调用。实际测试是在印第安纳大学 计算机科学系 的 Odin 集群上进行的,该集群包含 128 个通过 Infiniband 连接的节点。每个节点包含 4GB 内存和两个 AMD Opteron 处理器。NetPIPE 基准测试使用 Intel C++ 编译器 9.0 版、Boost 1.35.0 版(预发布版)和 Open MPI 1.1 版进行编译。NetPIPE 结果如下:
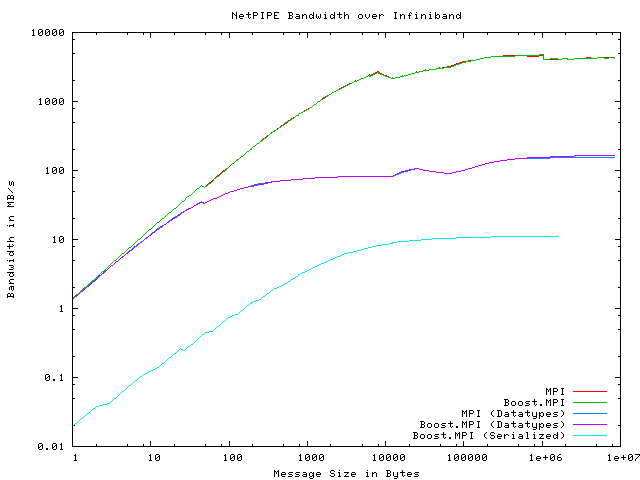
我们可以从这些 NetPIPE 结果中得出一些观察。首先,前两个图显示,对于基本类型,Boost.MPI 的性能与 MPI 相当。接下来的两个图显示,对于派生数据类型,Boost.MPI 的性能也与 MPI 相当,尽管 Boost.MPI 提供了一种比原始 MPI 更抽象、完全透明的构建派生数据类型的方法。派生数据类型的总体性能明显低于基本数据类型,但瓶颈在于底层 MPI 实现本身。最后,当强制 Boost.MPI 单独序列化字符时,性能会急剧下降。这种情况是 Boost.MPI 最糟糕的情况,因为我们正在序列化数百万个单独的字符。总的来说,Boost.MPI 提供的额外抽象并没有损害其性能。
