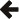


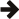
解析器以string作为输入,它代表模板元编程的字符串。例如,字符串"Hello World!"可以按以下方式定义
string<'H','e','l','l','o',' ','W','o','r','l','d','!'>
这种语法使得解析器的输入难以阅读。Metaparse 可与 C++98 编译器配合使用,但解析器的输入必须按上述方式定义。
基于 C++11 提供的constexpr特性,Metaparse 提供了一个宏BOOST_METAPARSE_STRING用于定义字符串
BOOST_METAPARSE_STRING("Hello World!")
这也定义了一个string,但是更易于阅读。以这种方式定义的字符串的最大长度是有限制的,但这个限制是可以配置的。它由BOOST_METAPARSE_LIMIT_STRING_SIZE宏指定。
错误使用编译时数据结构进行描述。它包含有关检测到错误的源位置的信息以及有关错误的描述。debug_parsing_error可用于显示错误消息。Metaparse 提供BOOST_METAPARSE_DEFINE_ERROR宏来定义简单的解析错误消息。
可以通过组合简单解析器来构建复杂的解析器。解析器库包含许多解析器组合子,它们从现有解析器构建新解析器。
例如,accept_when<Parser, Predicate, RejectErrorMsg>是一个解析器。它使用Parser来解析输入。当Parser拒绝输入时,组合子将返回Parser失败的错误。当Parser成功时,组合子会使用Predicate验证结果。如果谓词返回 true,则组合子接受输入,否则它会生成一条带有RejectErrorMsg消息的错误。
有了accept_when,就可以使用one_char来构建仅接受数字字符、仅接受空白字符等的解析器。例如,digit仅接受数字字符
typedef boost::metaparse::accept_when< boost::metaparse::one_char, boost::metaparse::util::is_digit, boost::metaparse::errors::digit_expected > digit;
成功解析的结果是某个值以及未解析的剩余字符串。剩余字符串可以由另一个解析器处理。解析器库提供了一个解析器组合子sequence,它以多个解析器作为参数,并从它们构建一个新解析器,该解析器
解析未知长度的列表是很常见的事情。例如,我们从简单的开始:文本是数字列表。例如
11 13 3 21
我们希望解析结果是这些值的总和。Metaparse 提供了一个int_解析器,我们可以用它来解析这些数字中的一个。Metaparse 提供了一个token组合子来消耗数字后的空白符。因此,下面的解析器解析一个数字及其后面的空白符
using int_token = token<int_>;
解析结果是一个装箱的整数值:已解析数字的值。例如,解析BOOST_METAPARSE_STRING("13 ")的结果是boost::mpl::int_<13>。
我们的示例输入是数字列表。每个数字都可以由int_token解析
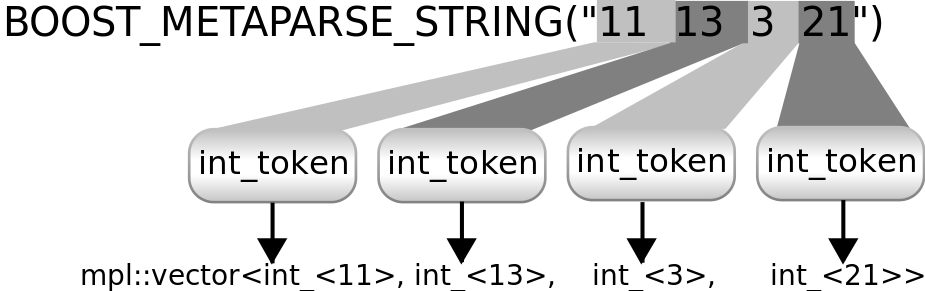
该图显示了int_token的重复应用如何解析示例输入。Metaparse 提供了一个repeated解析器来实现这一点。解析结果是一个类型列表:各个数字的列表。
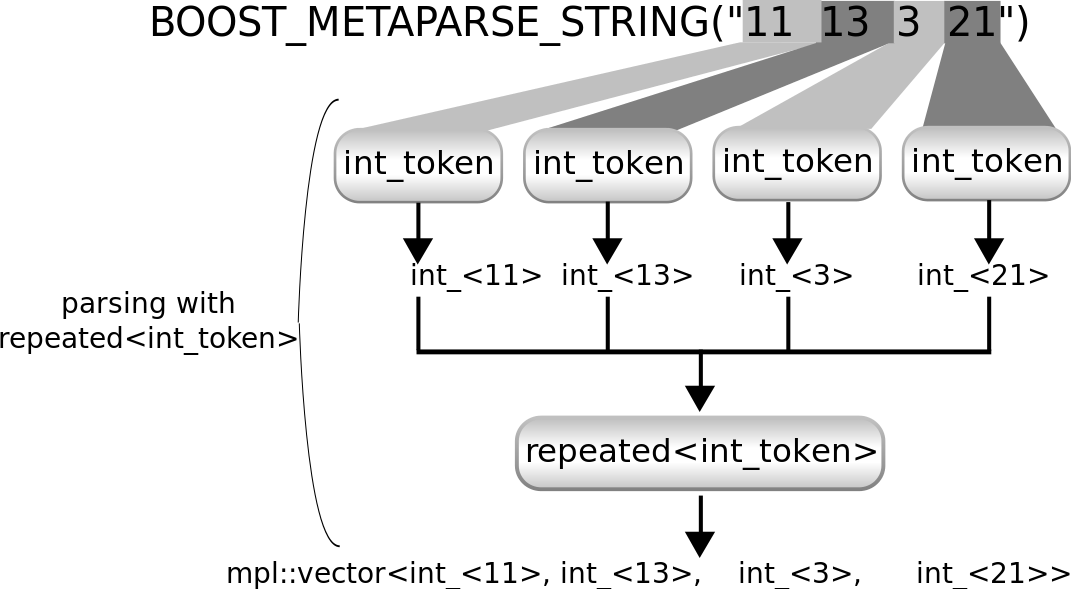
该图显示了repeated<int_token>的工作原理。它重复使用int_token解析器,并从它提供的结果中构建一个boost::mpl::vector。
但我们需要这些的总和,所以我们需要总结结果。我们可以通过包装我们的解析器repeated<int_token>与transform来实现。这让我们有机会指定一个函数来转换这个类型列表到其他值——在我们的例子中是列表中元素的总和。起初,我们暂时忽略如何总结向量中的元素。假设它可以由 lambda 表达式实现,并使用boost::mpl::lambda<...>::type来表示该 lambda 表达式。以下是一个使用transform和这个 lambda 表达式的示例
using sum_parser = transform< repeated<int_token>, boost::mpl::lambda<...>::type >;
该transform<>解析器组合子包装了repeated<int_token>以构建我们需要的解析器。这是一个显示其工作原理的图
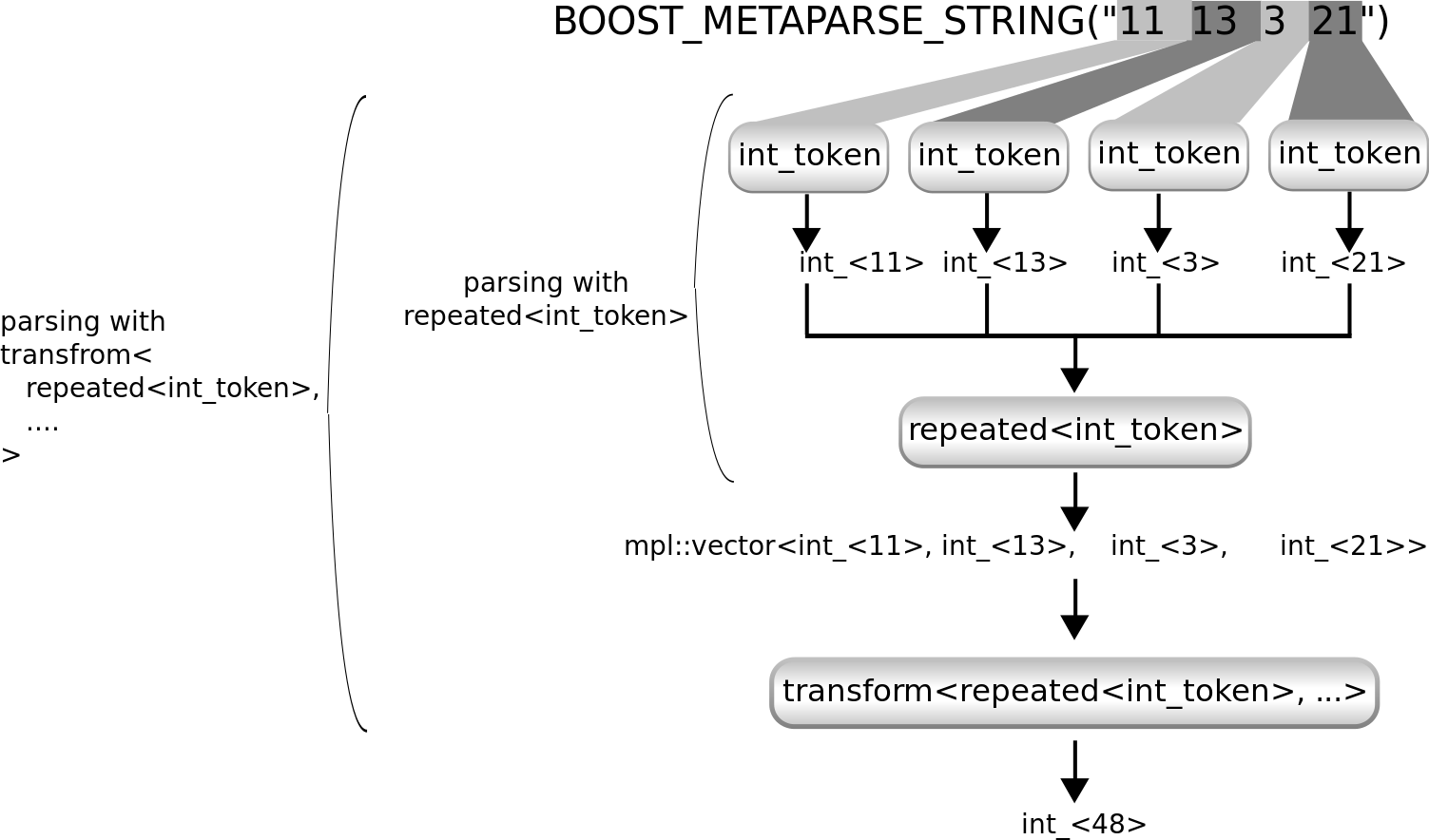
正如该图所示,transform<repeated<int_token>, ...>解析器使用repeated<int_token>解析输入,然后对解析结果进行一些处理。
让我们实现缺失的 lambda 表达式,它告诉transform如何更改来自repeated<int_token>的结果。我们可以通过使用 Boost.MPL 的fold或accumulate来总结类型列表中的数字。这是一个示例
using sum_op = mpl::lambda<mpl::plus<mpl::_1, mpl::_2>>::type; using sum_parser = transform< repeated<int_token>, mpl::lambda< mpl::fold<mpl::_1, mpl::int_<0>, sum_op> >::type >;
这里是上述图的扩展版本,展示了这里发生的情况
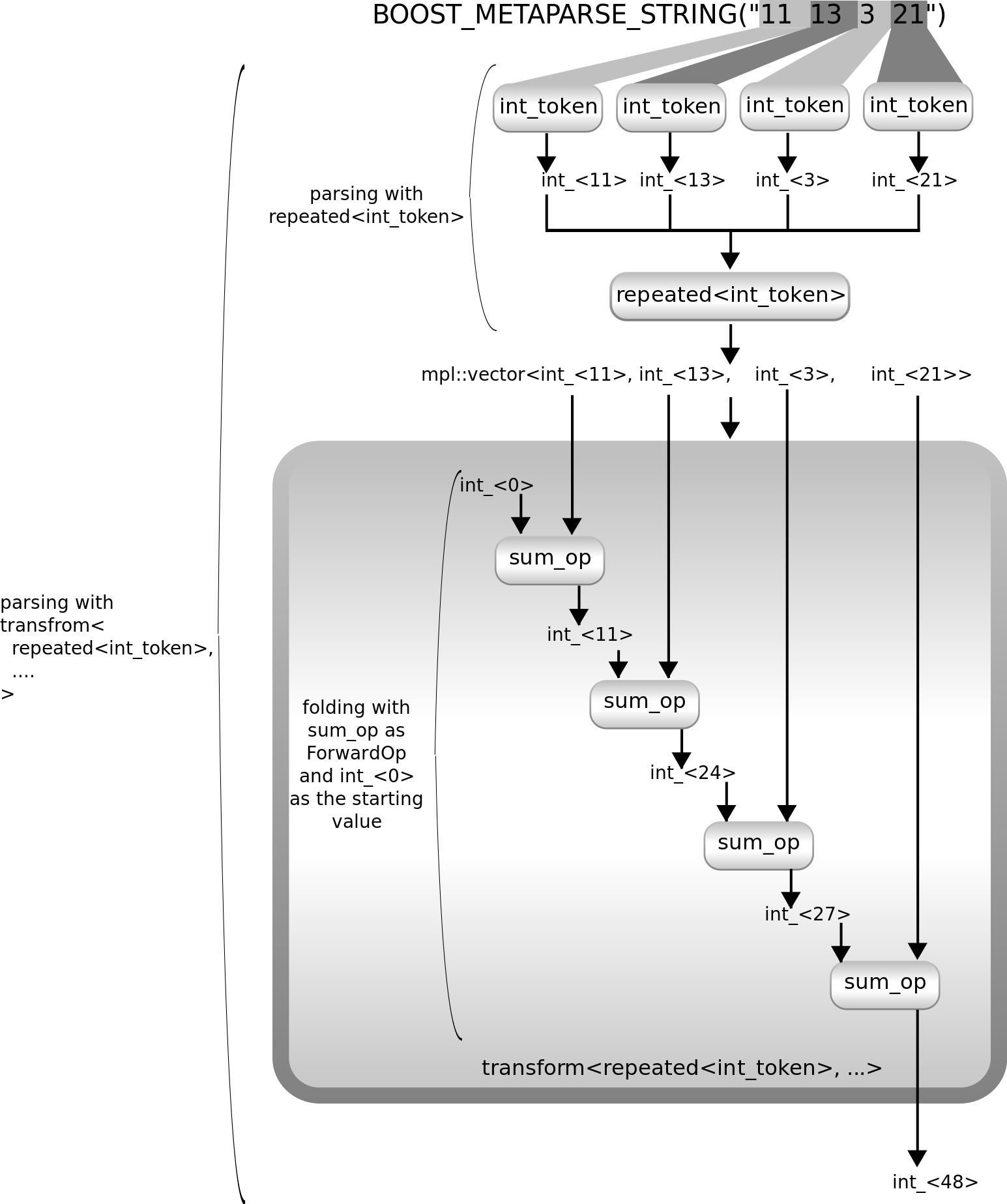
此示例解析输入,构建数字列表,然后遍历它并汇总值。它从fold的第二个参数int_<0>开始,并将数字列表中的每个项(即解析器repeated<int_token>的结果)逐一添加。
这样做是有效的,但是效率相当低:它有一个循环逐个解析整数,构建一个类型列表,然后遍历这个类型列表来汇总结果。在应用程序中使用模板元编程可能会严重影响编译器的内存使用和编译速度,因此我建议您谨慎对待这些事情。
Metaparse 提供了更有效的方式来实现相同的结果。您不需要两个循环:您可以将它们合并在一起,并在每次解析后立即将每个数字添加到您的汇总中。Metaparse 提供了foldl来实现这一点。
使用foldl,您需要指定
int_token)int_<0>)sum_op)我们的解析器可以这样实现
using better_sum_parser = foldl<int_token, mpl::int_<0>, sum_op>;
正如您所见,解析器的实现更简洁。这是一个显示使用此解析器解析输入时发生情况的图
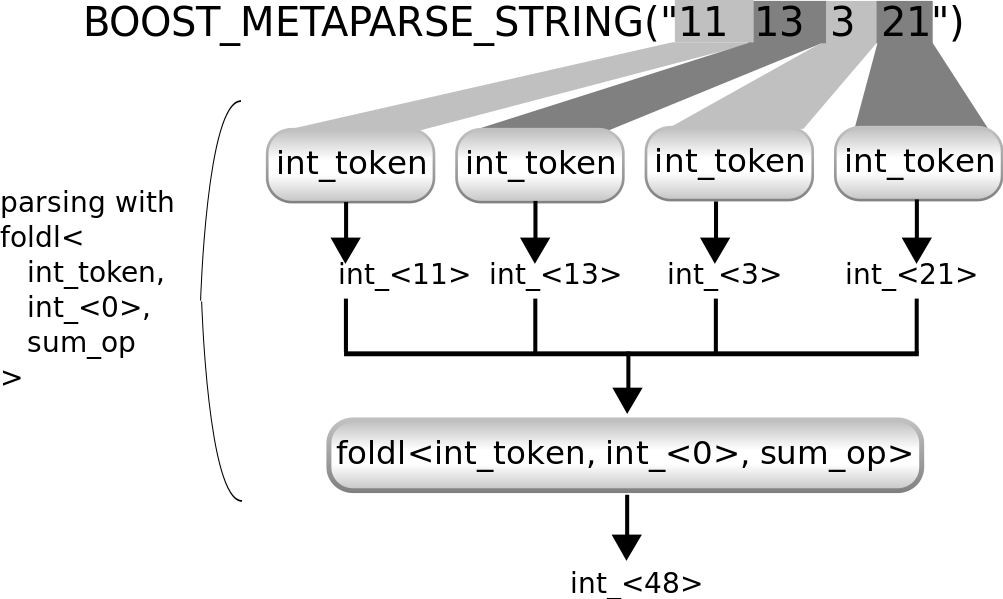
正如您所见,不仅解析器的实现更简洁,而且它通过做更少的工作实现了相同的结果。它通过重复应用int_token来解析输入,就像以前的解决方案一样。但它在不将类型列表作为内部步骤的情况下产生最终结果。以下是其工作原理
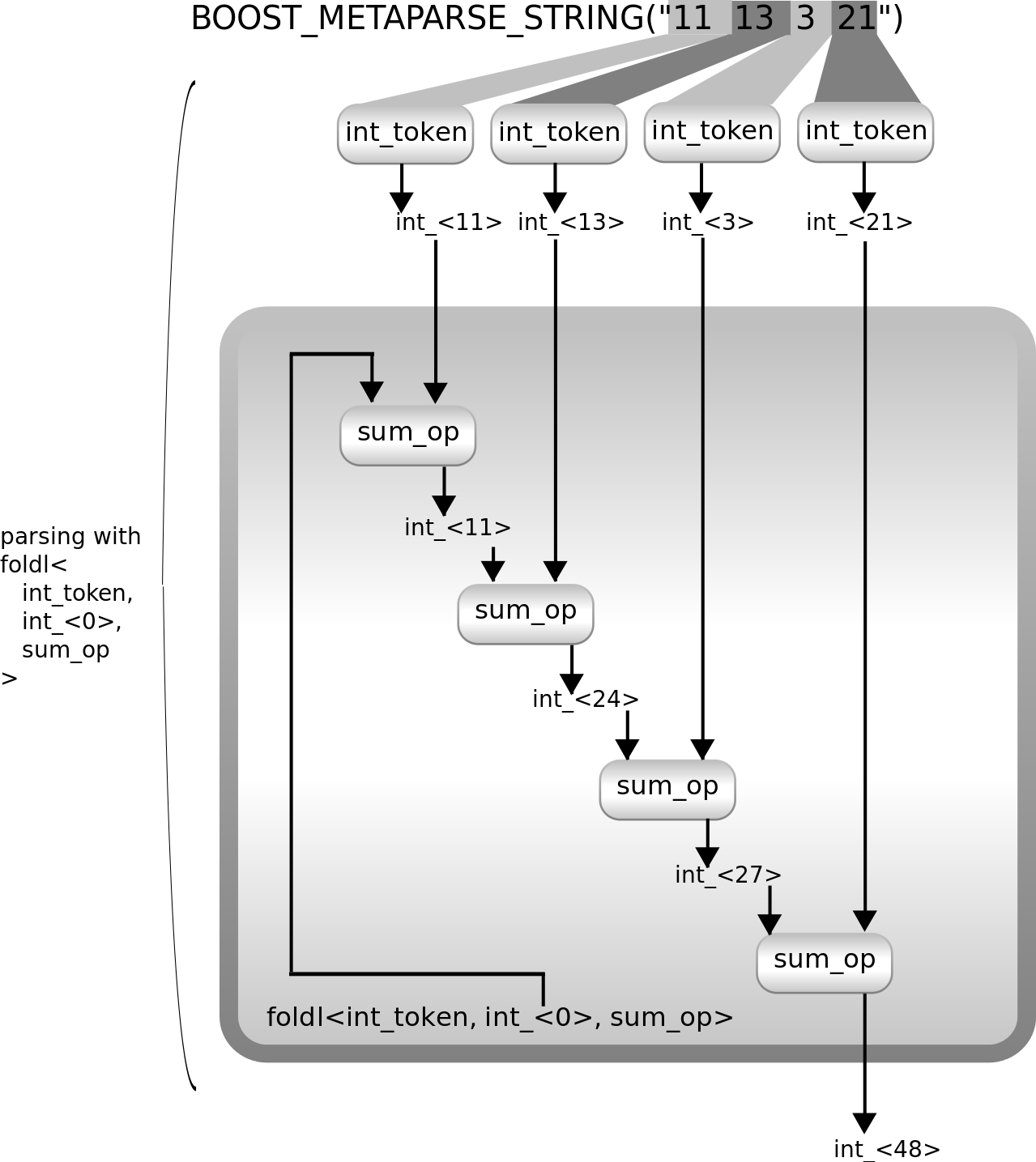
它使用sum_op来汇总重复的int_token应用的结果。此实现更有效。它接受空字符串作为有效输入:其总和为0。如果这对您来说是好的,那么您就完成了。如果您不想接受它,可以使用foldl1而不是foldl。(如果您选择了第一种方法并且想拒绝空字符串,Metaparse 还提供repeated1)
![[Note]](../../../doc/src/images/note.png) |
注意 |
|---|---|
请注意,如果您是第一次阅读本手册,您可能希望跳过本节,然后继续阅读Introducing foldl_start_with_parser。 |
您可能已经注意到 Metaparse 也提供了foldr。foldl 和foldr之间的区别在于结果汇总的方向。(l代表从左边,r代表从右边)这里有一个图显示了如果better_sum_parser使用foldr实现会发生什么
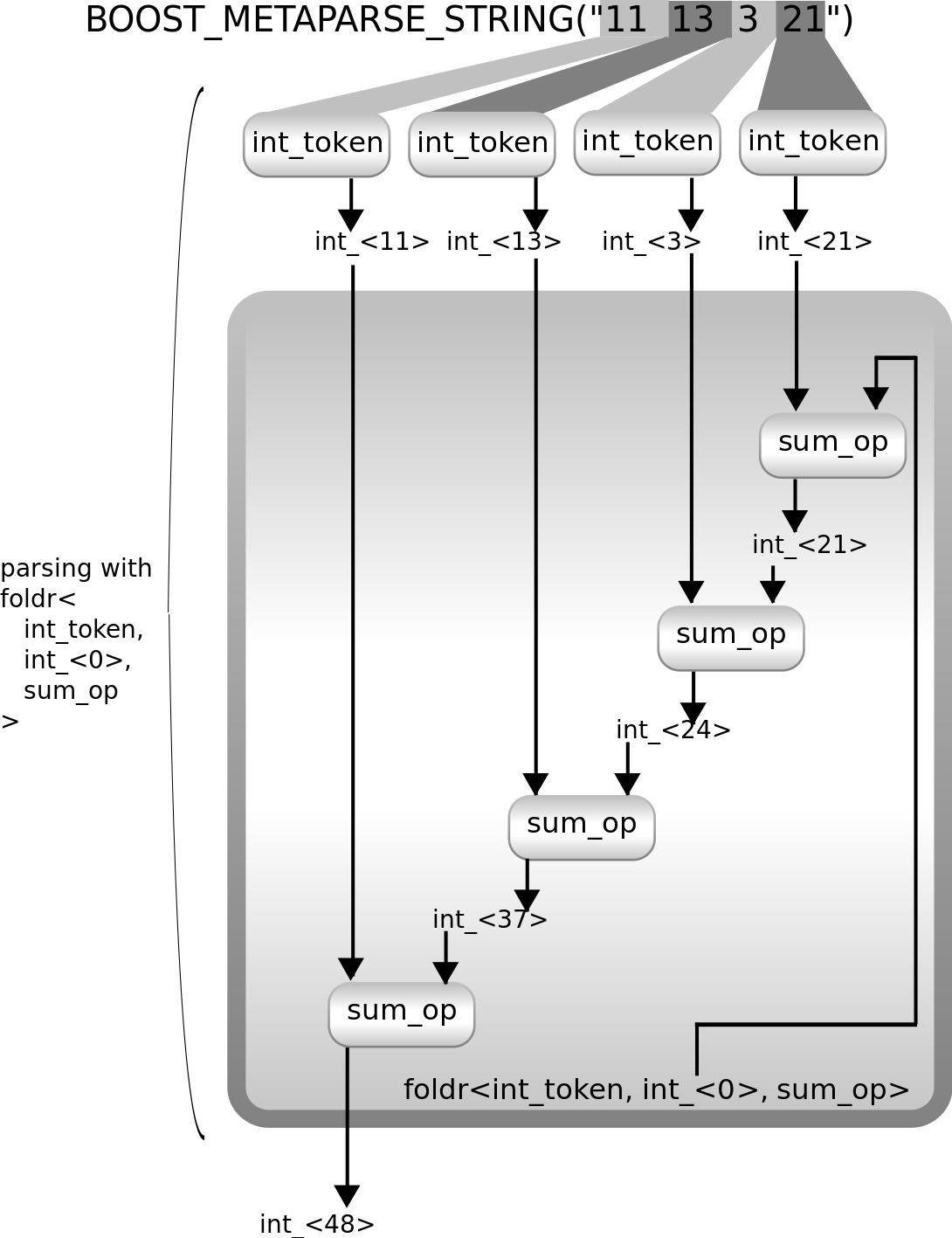
正如您所见,这与使用foldl非常相似,但来自int_token的各个应用的返回结果是按从右到左的顺序汇总的。由于sum_op是加法,它不影响最终结果,但在其他情况下可能会。
正如您可能期望的,Metaparse 也提供了foldr1,它从右边折叠并拒绝空输入。
让我们改变我们的小语言的语法。我们不再期望数字列表,而是期望数字用+符号分隔。我们的示例输入变成以下内容
BOOST_METAPARSE_STRING("11 + 13 + 3 + 21")
使用foldl或repeated解析它很困难:除了第一个之外,每个元素之前都必须有一个+符号。前面介绍的重复构造中没有一个提供了一种区别对待第一个元素的方法。
如果我们暂时忽略第一个数字,剩下的输入是"+ 13 + 3 + 21"。这可以很容易地由foldl(或repeated)解析
using plus_token = token<lit_c<'+'>>; using plus_int = last_of<plus_token, int_token>; using sum_parser2 = foldl<plus_int, int_<0>, sum_op>;
它使用plus_int,即last_of<plus_token, int_token>作为重复使用的解析器来获取数字。它这样做
plus_token解析+符号以及可能跟随它的任何空白符。int_token解析数字last_of将以上两项组合起来,按顺序使用这两个解析器,并只保留使用第二个解析器的结果(plus_token的解析结果被丢弃——我们不关心它)。这样,last_of<plus_token, int_token>返回数字的值作为解析结果,就像我们之前的解析器int_token一样。因此,它可以作为int_token在前面示例中的即插即用替换,并且我们获得了用于更新语言的解析器。或者至少是除了第一个数字之外的所有数字。
此foldl无法解析第一个元素,因为它期望每个数字前都有一个+符号。您可能会想到在上述方法中使+符号可选——不要这样做。它会使解析器同时接受"11 + 13 3 21",因为+符号在任何地方都是可选的。
您可以做的是使用int_token解析第一个元素,使用上述基于foldl的解决方案解析其余元素,并将两个结果相加。这留给读者作为练习。
Metaparse 提供foldl_start_with_parser来实现这一点。foldl_start_with_parser与foldl相同。区别在于,它不使用初始值来组合列表元素,而是接受一个初始解析器
using plus_token = token<lit_c<'+'>>; using plus_int = last_of<plus_token, int_token>; using sum_parser3 = foldl_start_with_parser<plus_int, int_token, sum_op>;
foldl_start_with_parser从应用该初始解析器开始,并使用它返回的结果作为折叠的初始值。之后,它执行与foldl相同的操作。下图显示了如何使用它来解析由+符号分隔的数字列表
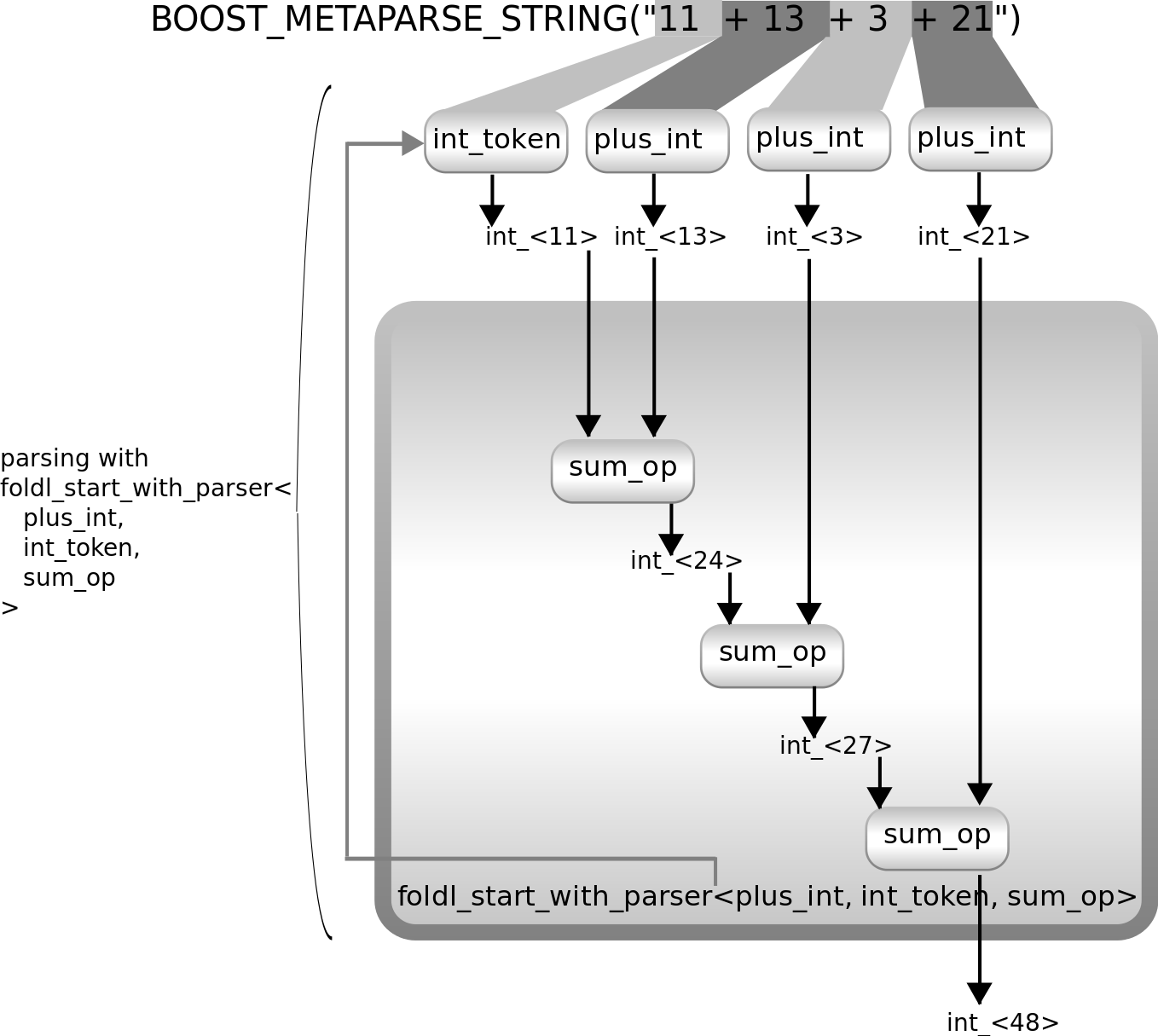
正如该图所示,它使用int_token开始解析数字列表,使用其值作为折叠的起始值(早期的方法使用int_<0>作为此起始值)。然后它通过多次使用plus_int来解析列表的所有元素。
|
注意 |
|---|---|
请注意,如果您是第一次阅读本手册,您可能希望跳过本节,而是尝试使用 |
foldl_start_with_parser有它的从右边的配对,foldr_start_with_parser。它使用与foldl_start_with_parser相同的元素,但顺序不同。这里有一个使用foldr_start_with_parser实现的示例语言解析器
using plus_token = token<lit_c<'+'>>; using int_plus = first_of<int_token, plus_token>; using sum_parser4 = foldr_start_with_parser<int_plus, int_token, sum_op>;
请注意,它使用int_plus而不是plus_int。这是因为初始折叠值的解析器是在int_plus已尽可能多次地解析输入后使用的。第一次听起来可能很奇怪,但下图应该有助于您理解其工作原理
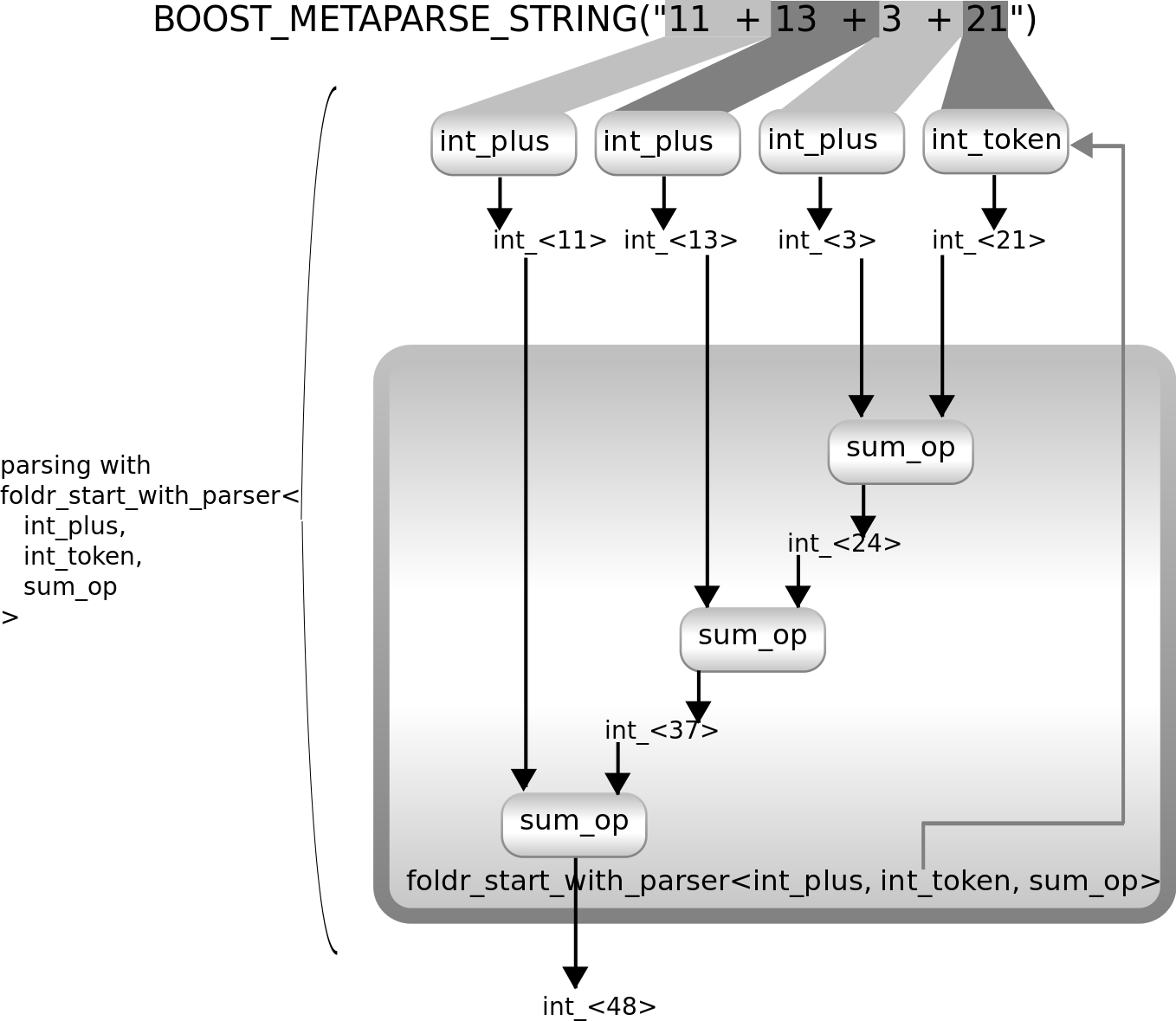
正如您所见,它以重复应用于输入的解析器开始,因此,我们不再重复解析plus_token int_token,而是需要重复解析int_token plus_token。最后一个数字后面没有+,因此int_plus无法解析它,它会停止迭代。foldr_start_with_parser然后使用另一个解析器int_token来解析输入。它成功了,它返回的结果用作从右开始折叠的起始值。
|
注意 |
|---|---|
请注意,如上所述, |
使用foldl_start_with_parser构建的解析器,我们可以解析输入(当输入正确时)。但是,情况并非总是如此。例如,考虑以下输入
BOOST_METAPARSE_STRING("11 + 13 + 3 + 21 +")
这是一个无效的表达式。然而,如果我们使用前面介绍的基于foldl_start_with_parser的解析器(sum_parser3)来解析它,它会接受输入,结果是48。这是因为foldl_start_with_parser尽可能地解析输入。它解析第一个int_token(11),然后开始解析plus_int元素(+ 13,+ 3,+ 21)。解析完所有这些之后,它会尝试使用plus_int解析剩余的" +"输入,但plus_int失败了,因此foldl_start_with_parser在+ 21之后停止。
问题在于解析器解析了从开头开始的最长子表达式,该子表达式代表一个有效表达式。其余部分被忽略。解析器可以被entire_input包装,以确保拒绝末尾有无效额外字符的表达式,但是,这并不能使错误消息有用。(entire_input只能告诉无效表达式的作者,在+ 21之后有问题。)
Metaparse 提供了foldl_reject_incomplete_start_with_parser,它执行的操作与foldl_start_with_parser相同,不同之处在于,一旦找不到进一步的重复,它会检查重复的解析器(在我们示例中是plus_int)在哪里失败。当它可以取得任何进展时(例如,它找到一个+符号),那么foldl_reject_incomplete_start_with_parser就会假设表达式的作者打算让重复次数更长,但犯了一个错误,并传播了来自最后一个损坏表达式的错误消息。
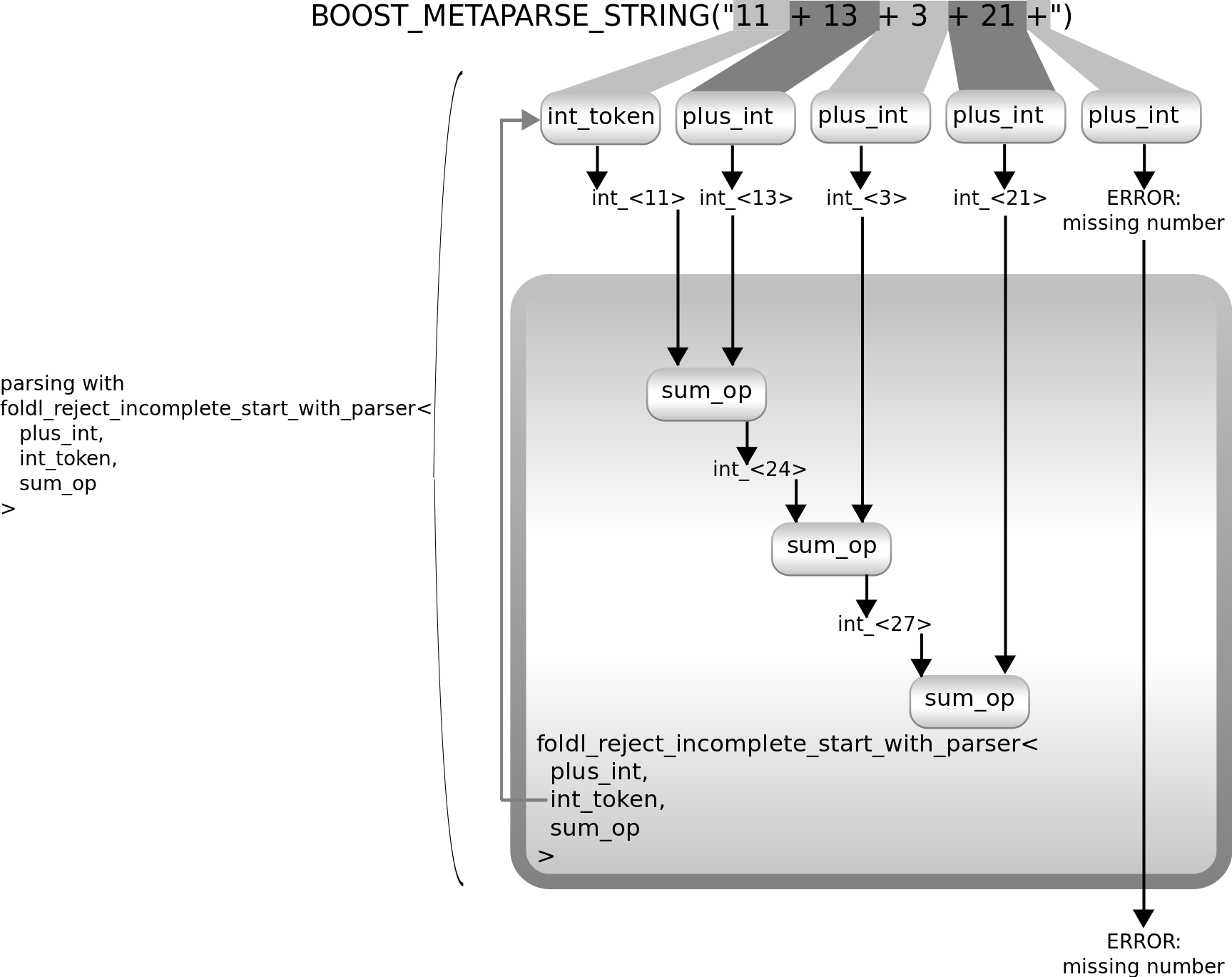
上图显示了foldl_reject_incomplete_start_with_parser如何解析示例无效输入及其失败情况。这可用于从解析器中获得更好的错误报告。
其他折叠解析器也有它们的f版本。(例如,foldr_reject_incomplete,foldl_reject_incomplete1,等等)。
您可能已经注意到,存在很多不同的折叠解析器组合器。为了帮助您找到合适的解析器,使用了以下命名约定:
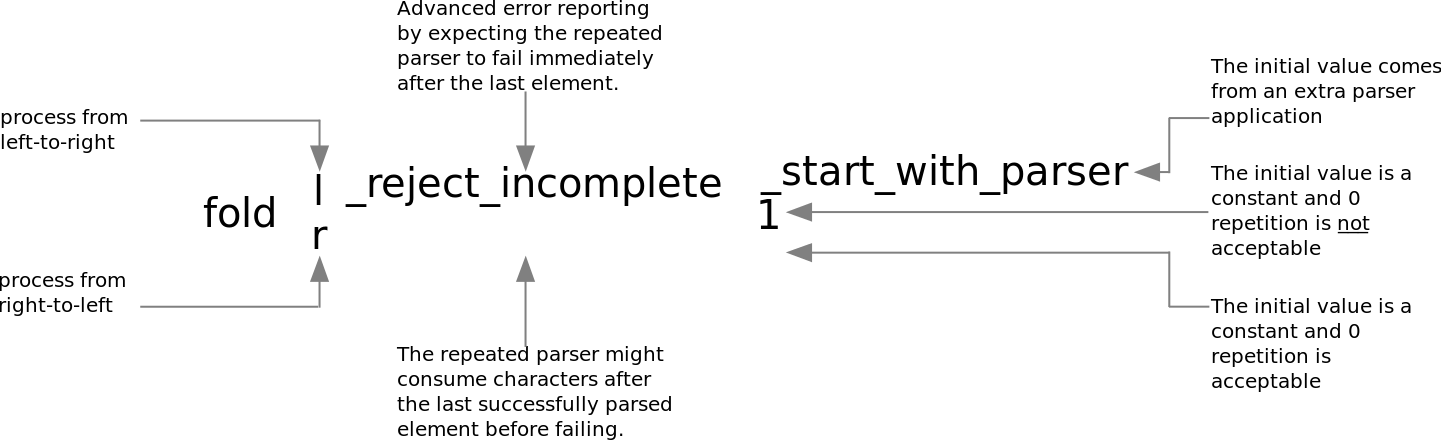
|
注意 |
|---|---|
请注意,没有 |
使用 Metaparse 构建的解析器是在编译时解析文本(或代码)的模板元程序。以下是可以作为解析“结果”的事物的列表:
printf 格式字符串并返回预期参数的类型列表(例如 boost::mpl::vector)的解析器。boost::xpressive::sregex 对象。有关示例,请参阅 Metaparse 的 regex 示例。compile_to_native_code 示例。meta_hs 示例。Metaparse 提供了一种以类似于 EBNF 的语法定义语法的方法。可以使用 grammar 模板来定义语法。它的用法如下:
grammar<BOOST_METAPARSE_STRING("plus_exp")> ::import<BOOST_METAPARSE_STRING("int_token"), token<int_>>::type ::rule<BOOST_METAPARSE_STRING("ws ::= (' ' | '\n' | '\r' | '\t')*")>::type ::rule<BOOST_METAPARSE_STRING("plus_token ::= '+' ws"), front<_1>>::type ::rule<BOOST_METAPARSE_STRING("plus_exp ::= int_token (plus_token int_token)*"), plus_action>::type
上面的代码从语法定义中定义了一个解析器。语法的起始符号是 plus_exp。以 ::rule 开头的行定义了规则。规则可以选择性地包含语义动作,语义动作是一个在应用规则后转换解析结果的元函数类。现有的解析器可以绑定到名称,并通过导入在规则中使用。以 ::import 开头的行将现有解析器绑定到名称。
语法定义的最终结果是一个解析器,可以将其提供给其他解析器组合器或直接使用。鉴于语法可以导入现有解析器并构建新的解析器,它们本身也是解析器组合器。
Metaparse 基于模板元编程,然而,C++11 提供了 constexpr,它也可以用于编译时解析。虽然基于 constexpr 实现解析器对于 C++ 开发者来说更容易,因为它的语法类似于语言的常规语法,但解析的结果必须是一个 constexpr 值。基于模板元编程的解析器可以将类型作为解析的结果。这些类型可以是装箱的 constexpr 值,也可以是元函数类、在运行时可调用的带有静态函数的类等。
当一个用 Metaparse 构建的解析器需要一个子解析器来处理输入文本的一部分并生成 constexpr 值作为解析结果时,可以使用 constexpr 函数来实现子解析器。Metaparse 可以与它们集成,并将它们的结果提升到 C++ 模板元编程中。可以在示例中找到一个演示此功能的示例(constexpr_parser)。这种能力使得 Metaparse 可以与基于 constexpr 的解析库集成。
可以使用 Metaparse 为 上下文无关文法 编写解析器。然而,这并不是可以使用的最通用的文法类别。由于 Metaparse 是一个高度可扩展的框架,目前尚不清楚 Metaparse 本身的极限是什么。例如,Metaparse 提供了 accept_when 解析器组合器。它可以用于为启用/禁用特定规则提供任意谓词。甚至可以提供整个文法的图灵机(作为一个 元函数)作为谓词,因此可以构建可使用图灵机解析的 无限制文法 的解析器。请注意,这样的解析器将不被认为是使用 Metaparse 构建的解析器,然而,尚不清楚一个解决方案能走多远,同时仍被认为是使用 Metaparse。
Metaparse 假定解析器是 确定性的,因为它们只有一个“结果”。当然,可以编写返回一个集合(或列表或其他容器)作为“一个”结果的解析器和组合器,但这可以被认为是构建一个新的解析器库。对于 Metaparse 没有明确的界限。
Metaparse 支持构建 自顶向下解析器,并且不支持 左递归,因为它会导致无限递归。 右递归 是支持的,然而,在大多数情况下,迭代解析器组合器 提供了更好的选择。
