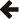


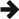
#include <boost/math/distributions/hypergeometric.hpp>
namespace boost{ namespace math{ template <class RealType = double, class Policy = policies::policy<> > class hypergeometric_distribution; template <class RealType, class Policy> class hypergeometric_distribution { public: typedef RealType value_type; typedef Policy policy_type; // Construct: hypergeometric_distribution(uint64_t r, uint64_t n, uint64_t N); // r=defective/failures/success, n=trials/draws, N=total population. // Accessors: uint64_t total()const; uint64_t defective()const; uint64_t sample_count()const; }; typedef hypergeometric_distribution<> hypergeometric; }} // namespaces
超几何分布描述了从总 population N 中抽取样本 n 后,出现的“事件”数量 k,且为不放回抽样。
假设我们有一个包含 N 个对象的样本,其中 r 个是“有缺陷的”,N-r 个是“无缺陷的”(也使用术语“成功/失败”或“红色/蓝色”)。 如果我们不放回地抽取 n 个物品,那么样本中恰好有 k 个物品是有缺陷的概率是多少? 答案由超几何分布的 pdf f(k; r, n, N) 给出,而 k 个或更少缺陷的概率由 F(k; r, n, N) 给出,其中 F(k) 是超几何分布的 CDF。
![[Note]](../../../../../../../doc/src/images/note.png) |
注意 |
|---|---|
与此库中几乎所有其他分布不同,超几何分布是严格离散的:它不能扩展到其参数或随机变量的实数值参数。 |
下图显示了当“有缺陷”物品的比例变化时,分布如何变化,同时保持总体和样本大小不变
请注意,由于分布在参数 n 和 r 中是对称的,如果我们更改样本大小并保持总体和“有缺陷”比例不变,那么我们基本上会获得相同的图表
hypergeometric_distribution(uint64_t r, uint64_t n, uint64_t N);
构造一个超几何分布,总体为 N 个对象,其中 r 个是有缺陷的,从中抽取 n 个样本。
uint64_t total()const;
返回对象总数 N。
uint64_t defective()const;
返回 population N 中有缺陷的对象数 r。
uint64_t sample_count()const;
返回从 population N 中抽取的对象数 n。
![[Warning]](../../../../../../../doc/src/images/warning.png) |
警告 |
|---|---|
参数的命名/符号和顺序令人困惑,没有两个实现是相同的! 请参阅 Wolfram Mathematica 超几何分布 和 Wikipedia 超几何分布 以及 Python scipy.stats.hypergeom。 |
支持所有分布通用的常用非成员访问器函数:累积分布函数、概率密度函数、分位数、风险函数、累积风险函数、__logcdf、__logpdf、均值、中位数、众数、方差、标准差、偏度、峰度、超额峰度、范围 和 支持。
随机变量的域是范围 [max(0, n + r - N), min(n, r)] 中的 64 位无符号整数。 如果随机变量超出此范围,或者不是整数值,则会引发 domain_error。
![[Caution]](../../../../../../../doc/src/images/caution.png) |
注意 |
|---|---|
|
默认情况下,分位数函数将返回已向外舍入的整数结果。 也就是说,较低的分位数(概率小于 0.5 的分位数)向下舍入,而较高的分位数(概率大于 0.5 的分位数)向上舍入。 此行为确保如果请求 X% 分位数,则中心区域中将存在至少请求的覆盖率,并且尾部中将存在不超过请求的覆盖率。 可以使用 策略 更改此行为,以便以不同的方式舍入分位数函数。 强烈建议您在使用超几何分布的分位数函数之前,阅读教程 理解离散分布的分位数。 参考文档 描述了如何更改这些分布的舍入策略。 但是,请注意,分位数函数的实现方法始终返回整数值,因此尝试使用需要(或产生)实数值结果的 策略 将导致编译时错误。 |
对于小的 N,使得 N < boost::math::max_factorial<RealType>::value,则基于表格查找的结果给出几个 epsilon 的精度。 boost::math::max_factorial<RealType>::value 在 double 或 long double 精度下为 170。
对于较大的 N,使得 N < boost::math::prime(boost::math::max_prime),则计算只需要基本算术,精度通常 < 20 epsilon。 这处理了高达 104729 的 N。
对于 N > boost::math::prime(boost::math::max_prime),精度会迅速下降,N = 110000 时会丢失 5 或 6 位十进制数字。
一般来说,对于非常大的 N,用户应预期在计算过程中会丢失 log10N 位十进制精度,对于 N >= 1015,结果将变得毫无意义。
有三组测试:我们的实现是根据 Mathematica 此分布的实现生成的值表进行测试的。 我们还针对使用在线计算器 http://stattrek.com/Tables/Hypergeometric.aspx 计算的一些抽样值对我们的实现进行健全性检查。 最后,我们使用此实现和 NTL::RR 针对一些高精度测试数据测试精度。 矩(均值到峰度)的抽样测试值来自 Mathematica 超几何分布,并且与 Wikipedia 超几何分布 和 Python scipy.stats.hypergeom 的实现一致。
PDF 可以使用以下公式直接计算
但是,只有当最大阶乘保证不会溢出所使用的浮点表示时,才能直接使用此公式。 当 N < max_factorial<RealType>::value 时直接使用此公式,在这种情况下,阶乘的表格查找提供了快速而准确的实现方法。
对于较大的 N,使用“超几何分布函数的精确计算”,Trong Wu,ACM Transactions on Mathematical Software,第 19 卷,第 1 期,1993 年 3 月,第 33-43 页中描述的方法。 该方法依赖于一个事实,即存在一种简单的方法可以将阶乘分解为素数的乘积
其中 pi 是第 i 个素数,ei 是一个小的正整数或零,可以通过以下公式计算
此外,我们可以组合 PDF 表达式中的阶乘,直接将 PDF 产生为素数的乘积
这次指数 ei 为正数、负数或零。 实际上,在 ei 的计算中发生了如此程度的抵消,以至于许多 ei 为零,并且通常大多数 ei 的量级不超过 1 或 2。
素数乘积的计算需要小心以防止数值溢出,我们使用一种新颖的递归方法,该方法将计算分为一系列子乘积,每次下一个乘法会导致溢出或下溢时,都会启动一个新的子乘积。 子乘积存储在程序堆栈上的链表中,并以保证一旦计算出最后一个子乘积就不会发生溢出或不必要的下溢的顺序组合。
只要 N 小于我们素数表中存储的最大素数(目前为 104729),就可以使用此方法。 该方法相对较慢(计算指数需要最多时间),但只需要少量算术运算即可计算结果(实际上,一旦找到指数,就不存在仅涉及基本算术的更短方法),因此该方法比替代方法准确得多。
对于更大的 N,我们可以使用 lgamma 或直接组合 lanczos 近似值从阶乘计算 PDF,以避免通过对数进行计算。 我们使用后一种方法,因为它通常比使用 lgamma 通过对数计算更准确 1 或 2 位十进制数字。 但是,在 N > 104729 的这个区域中,用户应预期在最坏情况下在计算过程中丢失大约 log10N 位十进制数字。
CDF 及其补集是通过直接求和 PDF 来计算的。 我们首先确定 CDF 或其补集哪个可能较小,然后在 k 处计算 PDF(或者如果我们正在计算补集,则在 k+1 处计算),并通过递推关系计算连续的 PDF 值
直到我们到达分布域的末尾,或者下一个要相加的 PDF 值太小而无法影响结果。
分位数的计算方式与 CDF 类似:我们首先猜测我们更接近分布的哪一端,然后从这次分布的末尾开始求和 PDF,直到我们得到某个值 k,该值给出所需的 CDF。
中位数只是 0.5 处的分位数,其余属性通过以下方式计算








