

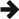
#include <boost/math/distributions/non_central_beta.hpp>
namespace boost{ namespace math{ template <class RealType = double, class Policy = policies::policy<> > class non_central_beta_distribution; typedef non_central_beta_distribution<> non_central_beta; template <class RealType, class Policy> class non_central_beta_distribution { public: typedef RealType value_type; typedef Policy policy_type; // Constructor: BOOST_MATH_GPU_ENABLED non_central_beta_distribution(RealType alpha, RealType beta, RealType lambda); // Accessor to shape parameters: BOOST_MATH_GPU_ENABLED RealType alpha()const; BOOST_MATH_GPU_ENABLED RealType beta()const; // Accessor to non-centrality parameter lambda: BOOST_MATH_GPU_ENABLED RealType non_centrality()const; }; }} // namespaces
非中心 beta 分布是 Beta 分布 的推广。
它被定义为比率
X = χm2(λ) / (χm2(λ) + χn2)
其中 χm2(λ) 是具有 m 个自由度的非中心 χ2 随机变量,而 χn2 是具有 n 个自由度的中心 χ2 随机变量。
这给出了一个 PDF,可以表示为 beta 分布 PDF 的泊松混合
其中 P(i;λ/2) 是在 i 处的离散泊松概率,均值为 λ/2,而 Ix'(α, β) 是不完全 beta 函数的导数。 这导致 CDF 的常用形式为
下图说明了分布如何随 λ 值的不同而变化
BOOST_MATH_GPU_ENABLED non_central_beta_distribution(RealType a, RealType b, RealType lambda);
构造一个非中心 beta 分布,其形状参数为 a 和 b,非中心参数为 lambda。
要求 a > 0、b > 0 和 lambda >= 0,否则调用 domain_error。
BOOST_MATH_GPU_ENABLED RealType alpha()const;
返回从中构造此对象的参数 a。
BOOST_MATH_GPU_ENABLED RealType beta()const;
返回从中构造此对象的参数 b。
BOOST_MATH_GPU_ENABLED RealType non_centrality()const;
返回从中构造此对象的参数 lambda。
支持大多数 常用的非成员访问器函数:累积分布函数、概率密度函数、分位数、均值、方差、标准差、中位数、众数、风险函数、累积风险函数、范围 和 支持。 对于此分布,这些函数标记为 BOOST_MATH_GPU_ENABLED,并且可以在主机和设备上运行。
均值和方差是使用超几何 pfq 函数以及 Wolfram 非中心 Beta 分布 中给出的关系实现的。
随机变量的域为 [0, 1]。
下表显示了在各种平台上使用各种浮点类型找到的峰值误差(以 epsilon 为单位)。 与 R Math 库 比较中的失败似乎主要是在概率非常小的极端情况下。 除非另有说明,否则任何比所示类型窄的浮点类型都将具有 有效零误差。
表 5.4. 非中心 beta CDF 的错误率
|
GNU C++ 版本 7.1.0 |
GNU C++ 版本 7.1.0 |
Sun 编译器版本 0x5150 |
Microsoft Visual C++ 版本 14.1 |
|
|---|---|---|---|---|
|
非中心 Beta,中等参数 |
最大值 = 0.998ε(平均值 = 0.0649ε) |
最大值 = 824ε(平均值 = 27.4ε) |
最大值 = 832ε(平均值 = 38.1ε) |
最大值 = 242ε(平均值 = 31ε) |
|
非中心 Beta,大型参数 |
最大值 = 1.18ε(平均值 = 0.175ε) |
最大值 = 2.5e+04ε(平均值 = 3.78e+03ε) |
最大值 = 2.57e+04ε(平均值 = 4.45e+03ε) |
最大值 = 3.66e+03ε(平均值 = 500ε) |
表 5.5. 非中心 beta CDF 补码的错误率
|
GNU C++ 版本 7.1.0 |
GNU C++ 版本 7.1.0 |
Sun 编译器版本 0x5150 |
Microsoft Visual C++ 版本 14.1 |
|
|---|---|---|---|---|
|
非中心 Beta,中等参数 |
最大值 = 0.998ε(平均值 = 0.0936ε) |
最大值 = 396ε(平均值 = 50.7ε) |
最大值 = 554ε(平均值 = 57.2ε) |
最大值 = 624ε(平均值 = 62.7ε) |
|
非中心 Beta,大型参数 |
最大值 = 0.986ε(平均值 = 0.188ε) |
最大值 = 6.83e+03ε(平均值 = 993ε) |
最大值 = 3.56e+03ε(平均值 = 707ε) |
最大值 = 1.25e+04ε(平均值 = 1.49e+03ε) |
PDF、CDF 补码和分位数函数的错误率大致相似。
有两组测试数据用于验证此实现:首先,我们可以与 R 库 生成的一些样本值进行比较。 其次,我们有使用此实现和区间算术计算的测试数据表 - 此数据应至少精确到小数点后 50 位 - 并且用于我们的准确性测试。
CDF 及其补码的评估方法如下
首先,我们确定两个值(CDF 或其补码)中哪个可能更小,交叉点被认为是分布的均值:为此,我们使用以下近似值:R. Chattamvelli 和 R. Shanmugam,“算法 AS 310:计算非中心 Beta 分布函数”,应用统计学,第 46 卷,第 1 期。(1997),第 146-156 页。
然后使用以下关系计算 CDF 或其补码
求和是通过从 i = λ/2 开始,然后在两个方向上递归进行的,使用泊松 PDF 和不完全 beta 函数的常用递归关系。 这是以下文献中描述的“方法 2”
Denise Benton 和 K. Krishnamoorthy,“计算连续分布的离散混合:非中心卡方、非中心 t 和样本多重相关系数的平方分布”,计算统计与数据分析 43 (2003) 249-267。
在以下文献中可以找到上述公式在非中心 beta 分布中的具体应用
Russell V. Lenth,“算法 AS 226:计算非中心 Beta 概率”,应用统计学,第 36 卷,第 2 期。(1987),第 241-244 页。
H. Frick,“算法 AS R84:关于算法 AS 226 的评论:计算非中心 Beta 概率”,应用统计学,第 39 卷,第 2 期。(1990),第 311-312 页。
Ming Long Lam,“评论 AS R95:关于算法 AS 226 的评论:计算非中心 Beta 概率”,应用统计学,第 44 卷,第 4 期。(1995),第 551-552 页。
Harry O. Posten,“非中心 Beta 分布函数的有效算法”,美国统计学家,第 47 卷,第 2 期。(1993 年 5 月),第 129-131 页。
R. Chattamvelli,“关于非中心 Beta 分布函数的注释”,美国统计学家,第 49 卷,第 2 期。(1995 年 5 月),第 231-234 页。
其中,Posten 参考资料提供了最完整的概述,并包括在 λ/2 处开始迭代的修改。
此实现与上述参考文献之间的主要区别在于,当最有效时直接计算补码,以及将总和累加到 -1 而不是在最后从 1 中减去结果:当结果接近 1 时,这可以显着减少所需的迭代次数。
PDF 是使用 Benton 和 Krishnamoorthy 的方法以及关系式计算的
分位数是使用专门修改的 bracket and solve 版本计算的,从分布的均值开始搜索根。(也尝试了 Cornish-Fisher 类型展开,虽然这在许多情况下非常接近根,但当它错误时,往往会引入非常病态的行为:可能需要对该领域进行更多研究)。





