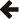


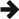
#include <boost/math/distributions/non_central_chi_squared.hpp>
namespace boost{ namespace math{ template <class RealType = double, class Policy = policies::policy<> > class non_central_chi_squared_distribution; typedef non_central_chi_squared_distribution<> non_central_chi_squared; template <class RealType, class Policy> class non_central_chi_squared_distribution { public: typedef RealType value_type; typedef Policy policy_type; // Constructor: BOOST_MATH_GPU_ENABLED non_central_chi_squared_distribution(RealType v, RealType lambda); // Accessor to degrees of freedom parameter v: BOOST_MATH_GPU_ENABLED RealType degrees_of_freedom()const; // Accessor to non centrality parameter lambda: BOOST_MATH_GPU_ENABLED RealType non_centrality()const; // Parameter finders: BOOST_MATH_GPU_ENABLED static RealType find_degrees_of_freedom(RealType lambda, RealType x, RealType p); template <class A, class B, class C> BOOST_MATH_GPU_ENABLED static RealType find_degrees_of_freedom(const complemented3_type<A,B,C>& c); BOOST_MATH_GPU_ENABLED static RealType find_non_centrality(RealType v, RealType x, RealType p); template <class A, class B, class C> BOOST_MATH_GPU_ENABLED static RealType find_non_centrality(const complemented3_type<A,B,C>& c); }; }} // namespaces
非中心卡方分布是卡方分布的推广。如果 Xi 是 ν 个独立的、服从正态分布的随机变量,均值为 μi,方差为 σi2,那么随机变量
服从非中心卡方分布。
非中心卡方分布有两个参数:ν,它指定自由度(即 Xi 的数量),以及 λ,它与随机变量 Xi 的均值有关,关系如下:
(请注意,某些参考文献将 λ 定义为上述总和的一半)。
这导致 PDF 为:
其中 f(x;ν) 是中心卡方分布 PDF,Iv(x) 是第一类修正贝塞尔函数。
下图说明了分布如何随 λ 值的不同而变化
BOOST_MATH_GPU_ENABLED non_central_chi_squared_distribution(RealType v, RealType lambda);
构造一个具有 ν 自由度和非中心参数 lambda 的卡方分布。
要求 ν > 0 且 lambda >= 0,否则调用 domain_error。
BOOST_MATH_GPU_ENABLED RealType degrees_of_freedom()const;
返回构造此对象时使用的参数 ν。
BOOST_MATH_GPU_ENABLED RealType non_centrality()const;
返回构造此对象时使用的参数 lambda。
BOOST_MATH_GPU_ENABLED static RealType find_degrees_of_freedom(RealType lambda, RealType x, RealType p);
此函数返回自由度 ν,使得: cdf(non_central_chi_squared<RealType, Policy>(v, lambda), x) == p
template <class A, class B, class C> BOOST_MATH_GPU_ENABLED static RealType find_degrees_of_freedom(const complemented3_type<A,B,C>& c);
当使用参数 boost::math::complement(lambda, x, q) 调用时,此函数返回自由度 ν,使得
cdf(complement(non_central_chi_squared<RealType, Policy>(v, lambda), x)) == q.
BOOST_MATH_GPU_ENABLED static RealType find_non_centrality(RealType v, RealType x, RealType p);
此函数返回非中心参数 lambda,使得
cdf(non_central_chi_squared<RealType, Policy>(v, lambda), x) == p
template <class A, class B, class C> BOOST_MATH_GPU_ENABLED static RealType find_non_centrality(const complemented3_type<A,B,C>& c);
当使用参数 boost::math::complement(v, x, q) 调用时,此函数返回非中心参数 lambda,使得
cdf(complement(non_central_chi_squared<RealType, Policy>(v, lambda), x)) == q.
支持所有分布通用的常用非成员访问器函数:累积分布函数、概率密度函数、分位数、风险函数、累积风险函数、__logcdf、__logpdf、均值、中位数、众数、方差、标准差、偏度、峰度、超额峰度、范围和支撑。对于此分布,所有非成员访问器函数都标记为 BOOST_MATH_GPU_ENABLED,并且可以在主机和设备上运行。
随机变量的域为 [0, +∞]。
有一个关于非中心卡方分布的已完成示例。
下表显示了在各种平台和各种浮点类型上发现的峰值误差(以 epsilon 为单位)。与 R Math 库的比较中的失败似乎主要发生在概率非常小的极端情况下。除非另有说明,否则任何比所示类型窄的浮点类型都将具有有效零误差。
表 5.6. 非中心卡方 CDF 的错误率
|
GNU C++ 版本 7.1.0 |
GNU C++ 版本 7.1.0 |
Sun 编译器版本 0x5150 |
Microsoft Visual C++ 版本 14.1 |
|
|---|---|---|---|---|
|
非中心卡方,中等参数 |
最大值 = 0.99ε(均值 = 0.0544ε) |
最大值 = 46.5ε(均值 = 10.3ε) |
最大值 = 115ε(均值 = 13.9ε) |
最大值 = 48.9ε(均值 = 10ε) |
|
非中心卡方,大型参数 |
最大值 = 1.07ε(均值 = 0.102ε) |
最大值 = 3.07e+03ε(均值 = 336ε) |
最大值 = 6.17e+03ε(均值 = 677ε) |
最大值 = 9.79e+03ε(均值 = 723ε) |
表 5.7. 非中心卡方 CDF 补码的错误率
|
GNU C++ 版本 7.1.0 |
GNU C++ 版本 7.1.0 |
Sun 编译器版本 0x5150 |
Microsoft Visual C++ 版本 14.1 |
|
|---|---|---|---|---|
|
非中心卡方,中等参数 |
最大值 = 0.96ε(均值 = 0.0635ε) |
最大值 = 107ε(均值 = 17.2ε) |
最大值 = 171ε(均值 = 22.8ε) |
最大值 = 98.6ε(均值 = 15.8ε) |
|
非中心卡方,大型参数 |
最大值 = 2.11ε(均值 = 0.278ε) |
最大值 = 5.02e+03ε(均值 = 630ε) |
最大值 = 5.1e+03ε(均值 = 577ε) |
最大值 = 5.43e+03ε(均值 = 705ε) |
分位数函数的错误率大致相似。应特别提及 mode 函数:此函数没有闭合形式,因此通过查找 PDF 的最大值以数值方式评估:原则上,这不能产生大于机器 epsilon 平方根的精度。
有两组测试数据用于验证此实现:首先,我们可以与已发布的数据进行比较,例如 Morgan C. Wang 和 William J. Kennedy 在《美国统计协会杂志》第 89 卷第 427 期(1994 年 9 月),第 878-887 页的“选定中心和非中心单变量概率函数的自验证计算”表 6。其次,我们有使用此实现和区间算术计算的测试数据表 - 此数据应至少精确到 50 位小数 - 并用于我们的精度测试。
CDF 及其补码的评估方式如下:
首先,我们确定两个值(CDF 或其补码)中哪个可能更小:为此,我们可以使用 Temme 的关系(参见“非中心卡方分布的渐近和数值方面”,N. M. Temme,Computers Math. Applic. Vol 25, No. 5, 55-63, 1993),即
F(ν,λ;ν+λ) ≈ 0.5
因此,当随机变量小于 ν+λ 时计算 CDF,当随机变量大于 ν+λ 时计算其补码。如有必要,然后从 1 中减去计算结果,以给出所需的结果(CDF 或其补码)。
对于非中心参数的小值,CDF 使用 Ding 的方法计算(参见“算法 AS 275:计算非中心 #2 分布函数”,Cherng G. Ding,Applied Statistics,Vol. 41, No. 2. (1992), pp. 478-482)。这使用以下级数表示:
这只需要一次调用 gamma_p_derivative,随后的项通过如上所示的递归计算。
对于较大的非中心参数值,Ding 的方法可能需要大量的项才能实现收敛。此外,最大项不是第一项,因此在极端情况下,第一项可能为零,导致结果为零,即使真值可能非零。
因此,当非中心参数大于 200 时,使用 Krishnamoorthy 的方法(参见“计算连续分布的离散混合:非中心卡方、非中心 t 和样本多重相关系数的平方分布”,Denise Benton 和 K. Krishnamoorthy,Computational Statistics & Data Analysis, 43, (2003), 249-267)。
此方法使用众所周知的总和:
其中 Pa(x) 是不完全伽马函数。
该方法从第 λ 项开始,这是泊松权重函数达到其最大值的地方,尽管这不一定是最大的总项。随后的项通过不完全伽马函数的正常递归关系计算,并且迭代向前和向后进行,直到达到足够的精度。应该注意的是,Pa(x) 向前方向的递归在数值上是不稳定的。但是,由于我们始终在级数中的最大项之后开始,因此数值不稳定性引入的速度比级数收敛的速度慢。
CDF 补码的计算使用 Krishnamoorthy 方法的扩展,鉴于
我们可以再次从第 λ' 项开始,并从那里在两个方向上进行,直到达到所需的精度。这次是不完全伽马函数 Qa(x) 的向后递归,它是不稳定的。但是,只要我们远在最大项之前开始,这在实践中就不是问题。
PDF 使用关系式直接计算:
其中 f(x;ν) 是中心卡方分布的 PDF,Iv(x) 是修正贝塞尔函数,请参见cyl_bessel_i。对于非中心参数的小值,使用与 cyl_bessel_i 相关的关系。但是,此方法对于较大的非中心参数值会失败,因此在这种情况下,使用 Benton 和 Krishnamoorthy 的方法评估无穷级数,以及连续项的常用递归关系。
分位数函数通过 CDF 的数值反演计算。Thomas Luu 的随机数生成分位数函数的快速准确并行计算,博士论文,2016提供了一个改进的起始猜测。
非中心卡方分布的众数没有闭合形式:它通过数值方式查找 PDF 的最大值来计算。同样,中位数通过分位数数值计算。
其余非成员函数使用以下公式:
Andrea van Aubel & Wolfgang Gawronski 在《应用数学与计算》141 (2003) 3-12 中调查并总结了非中心分布的一些分析特性(特别是单峰性和众数的单调性)。
Andrea van Aubel & Wolfgang Gawronski, Applied Mathematics and Computation, 141 (2003) 3-12.








